Text in Context: Basic Concepts
LIS 4/5693: Information Retrieval and Text Mining
Introduction
Information Retrieval (IR) is about finding the right documents
Natural Language Processing (NLP) is about understanding language
Text Mining is about discovering patterns and knowledge from large collections of text
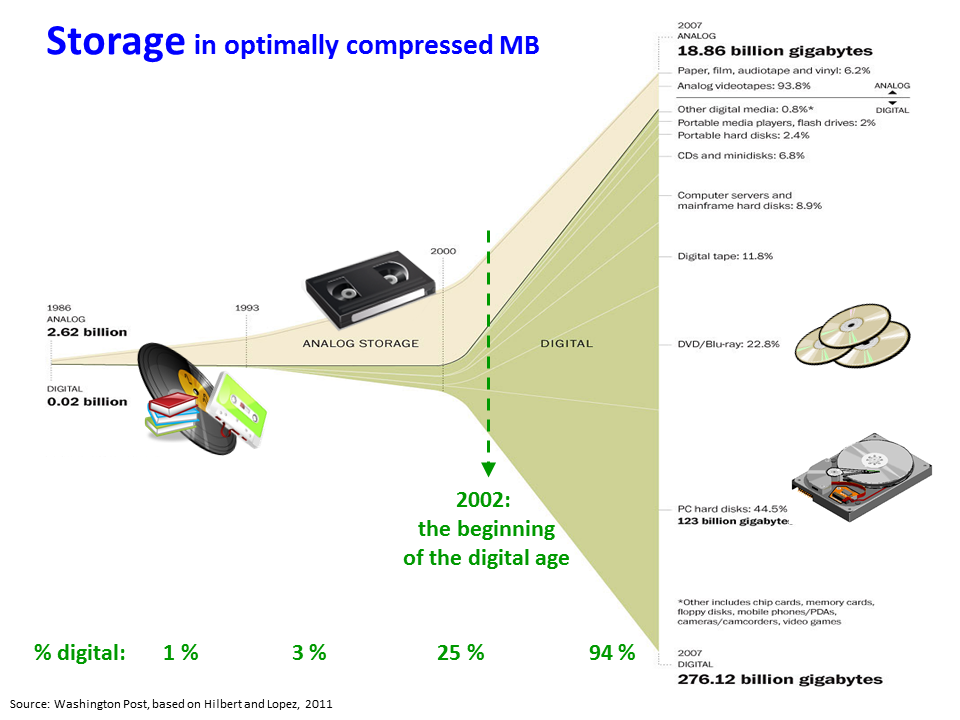
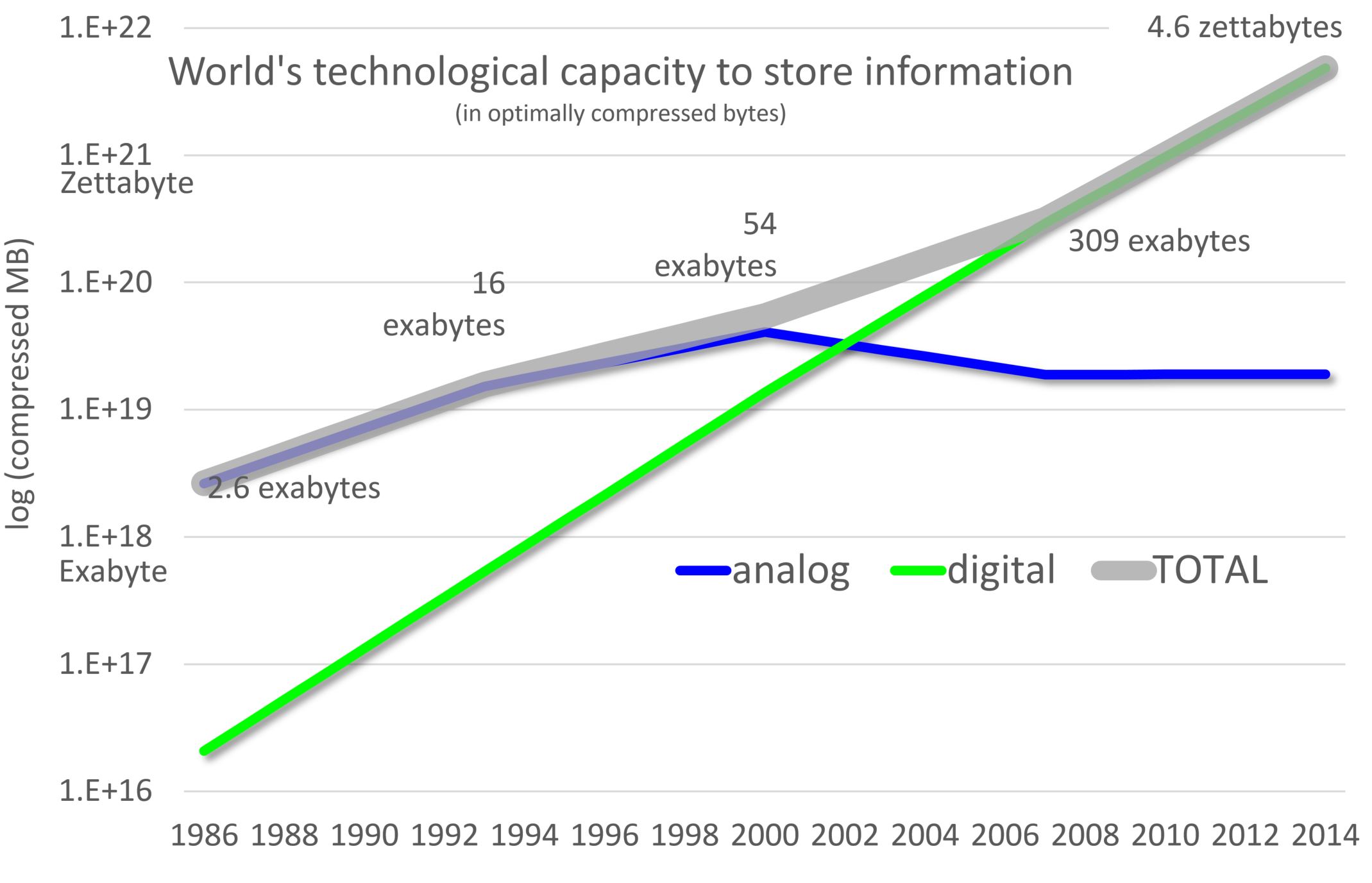
Exponential Growth of Data
Data and information generation in every discipline in the universe of knowledge has seen staggering growth
Storing, managing, querying, & retrieval of huge amount of data & information needs sophisticated procedures & advanced technologies
Nowadays, information collection is web-based and online which is vast and growing at an exponential rate
Information Retrieval
Definition
A process in which sets of records or documents are searched to find items which may help to satisfy an information need
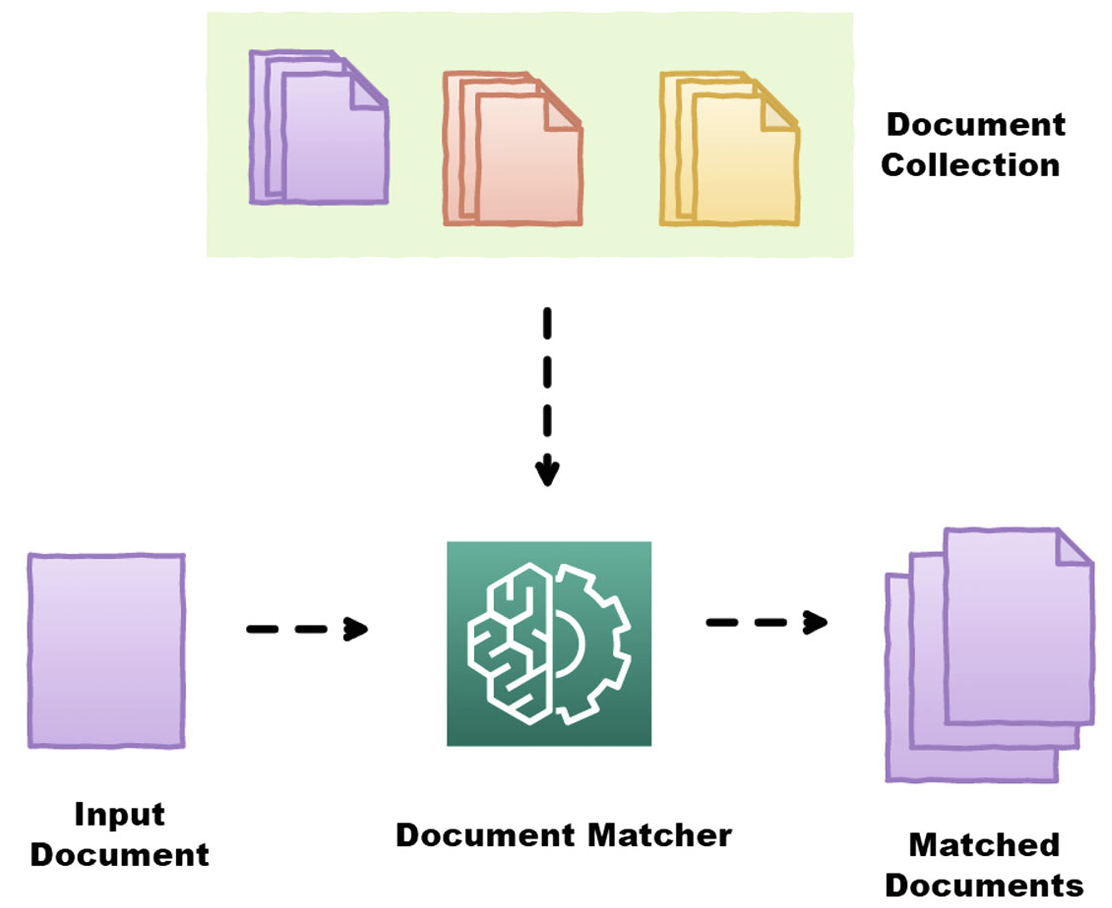
Brief History of Information Retrieval
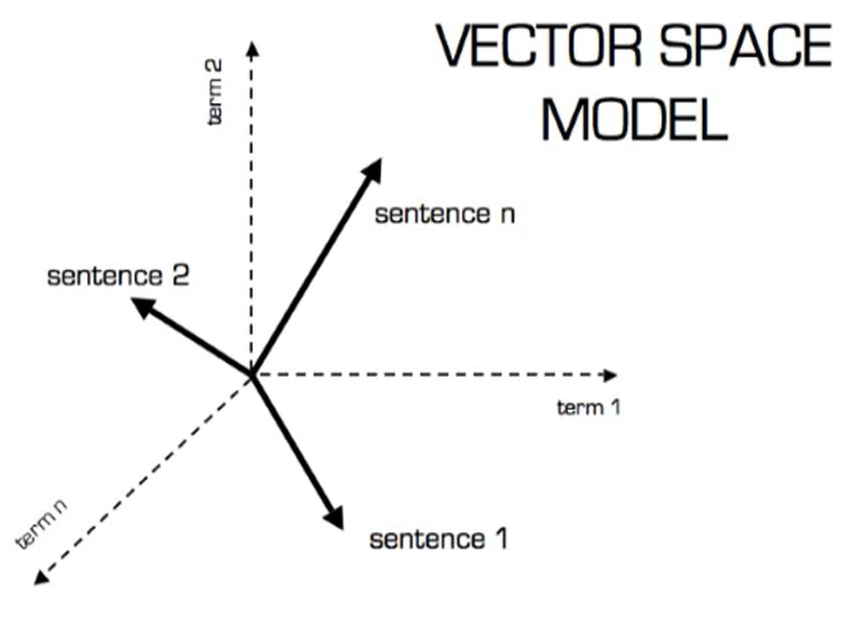
- System for the Mechanical Analysis and Retrieval of Text (SMART) was developed by Gerard Salton in Cornell University in 1960s. This system incorporated many important concepts like vector space model, relevance feedback, and Rocchio Classification
Brief History of Information Retrieval
J.W. Sammon (1969) gave the idea of visualization interface integrated to an IR system in his famous paper “A nonlinear mapping for data structure analysis”
First online systems–NLM’s AIM-TWX, MEDLINE; Lockheed’s Dialog; SDC’s ORBIT
- During 1966-67, F.W. Lancaster evaluated the MEDLARS (Medical Literature Analysis and Retrieval System)
Brief History of Information Retrieval
PageRank algorithm was developed at Stanford University by Larry Page and Sergey Brin in 1996
In 1997, Google Inc. was born which has now ruling dominantly in searching engine domain
Google personalized search started in 2005
Multimedia IR (Smeulders, Lew, Sebe) integrates into search in 2010
Semantic models came first in 2013-2014 such as Word2Vec, GloVe
Google introduces BERT in 2018
Conversational IR in assistants were introduced in 2020-2021 such as Alexa, Siri
Retrieval Augmented Genreration in 2022-2023
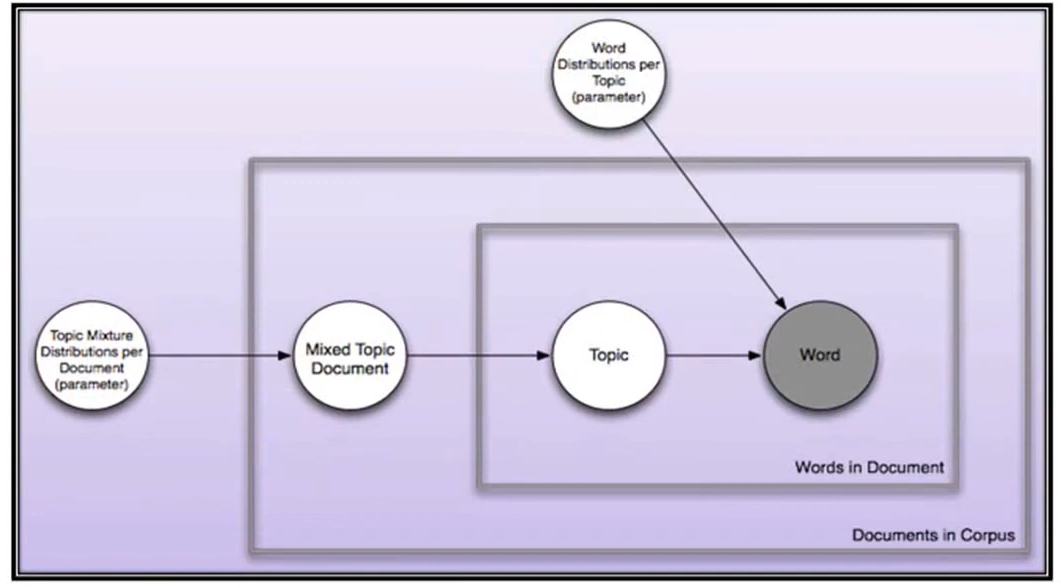
LSI gained huge popularity in WWW and was hugely used in Search Engine Optimization (SEO)
Latent Dirichlet allocation (LDA), a generative/topic model in NLP was developed by David Blei, Andrew NG, and Michael Jordan in 2003
Information Retrieval Systems
A specialized system for the description, storage, and retrieval of information representations: primarily information objects (text, images) and their surrogates (metadata, records). Operates by matching queries (representations of information need) with data (representations of information objects)
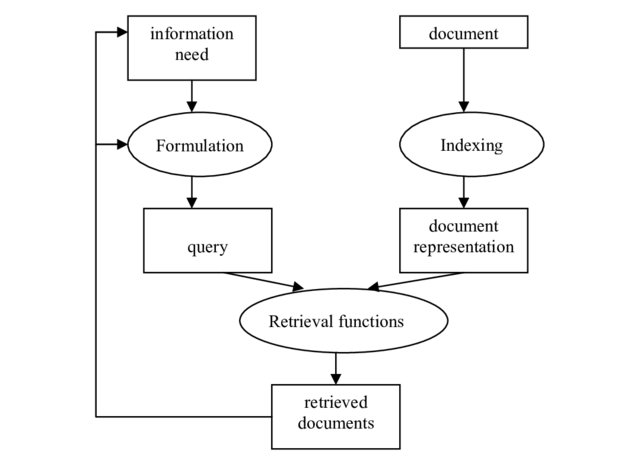
Components of IR systems
Knowledge system into which an IR system is implanted generally consists of three main components:
people in their role as information-processors
documents in their role as carriers of information
topics as representations
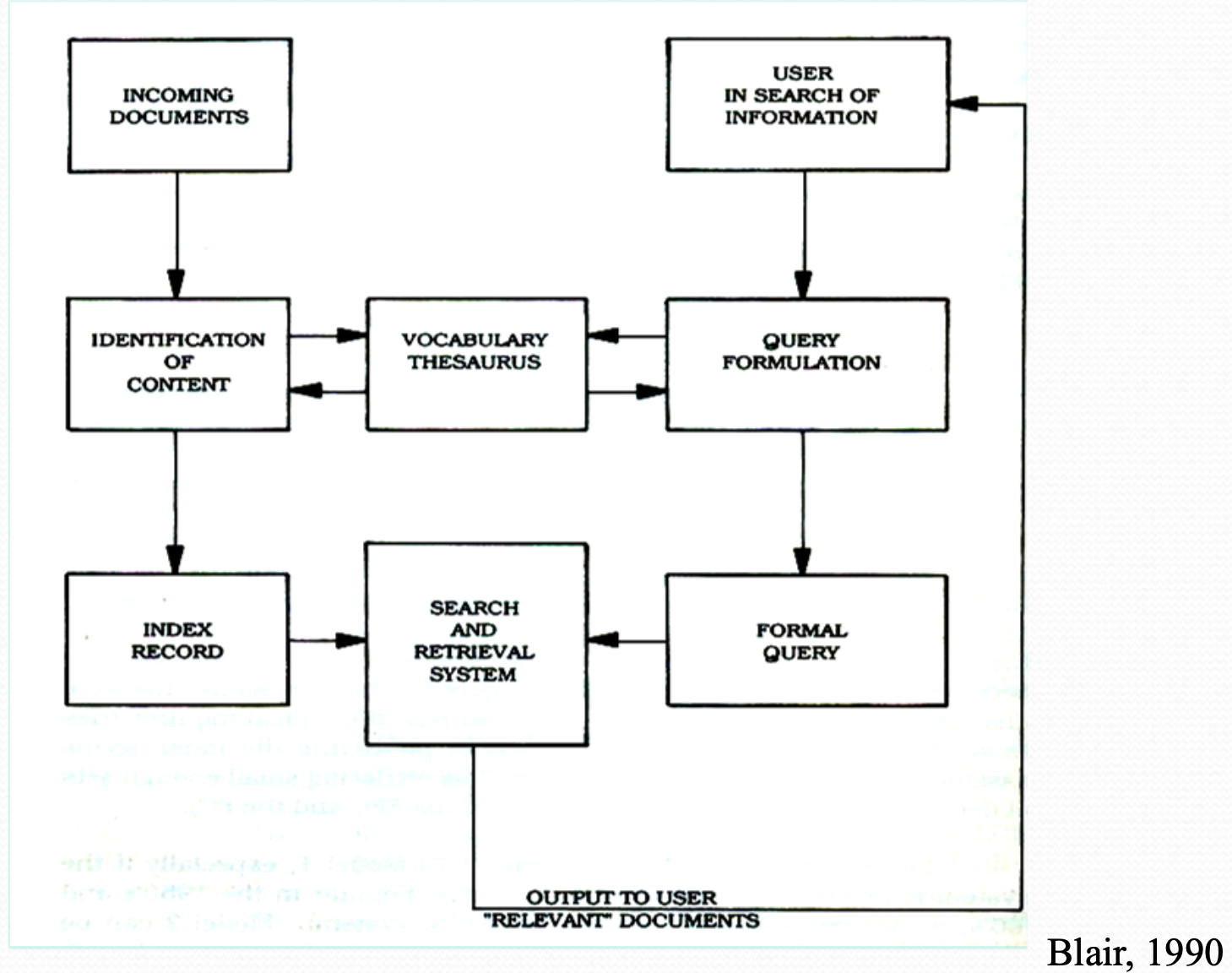
Model of IR System
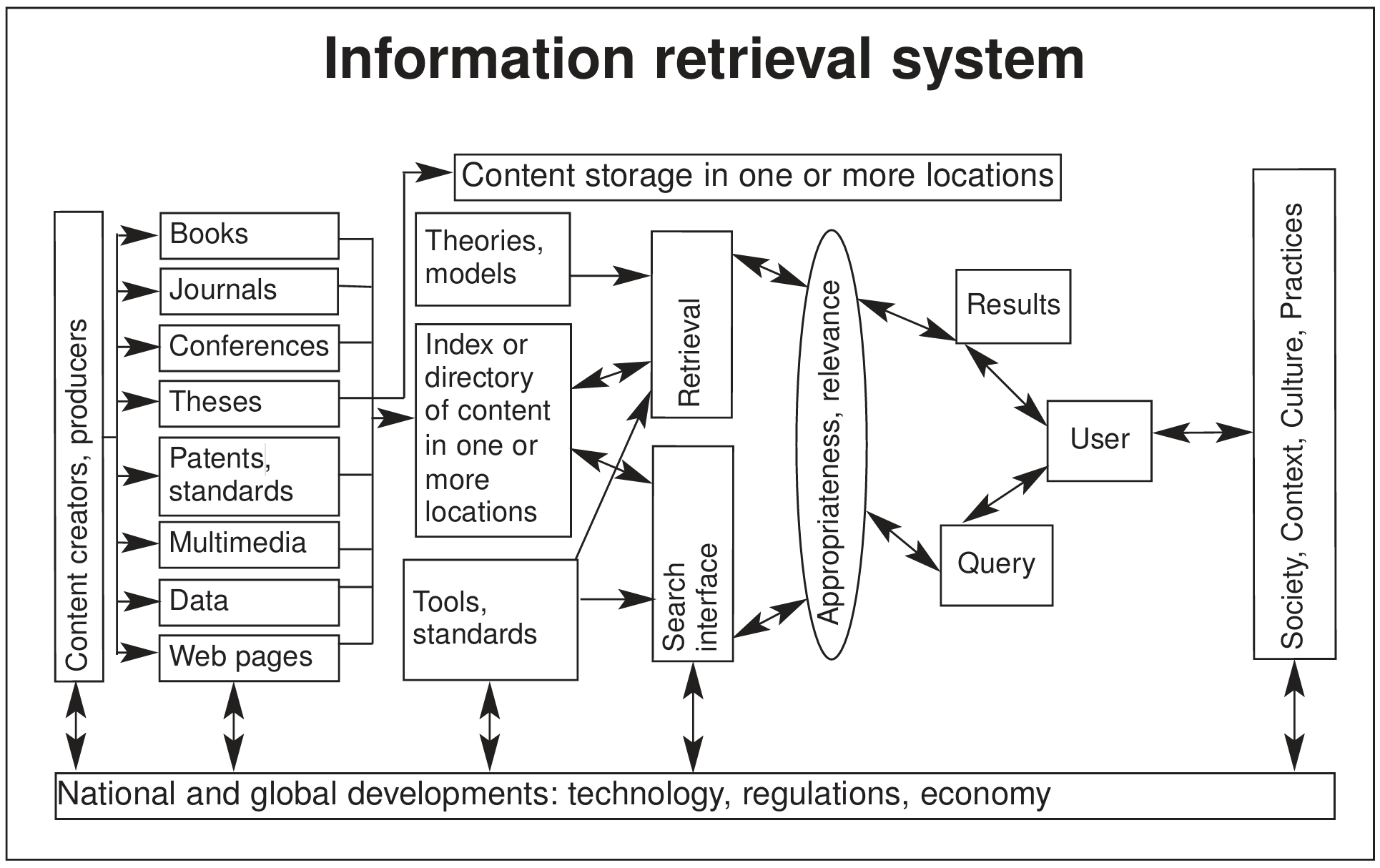
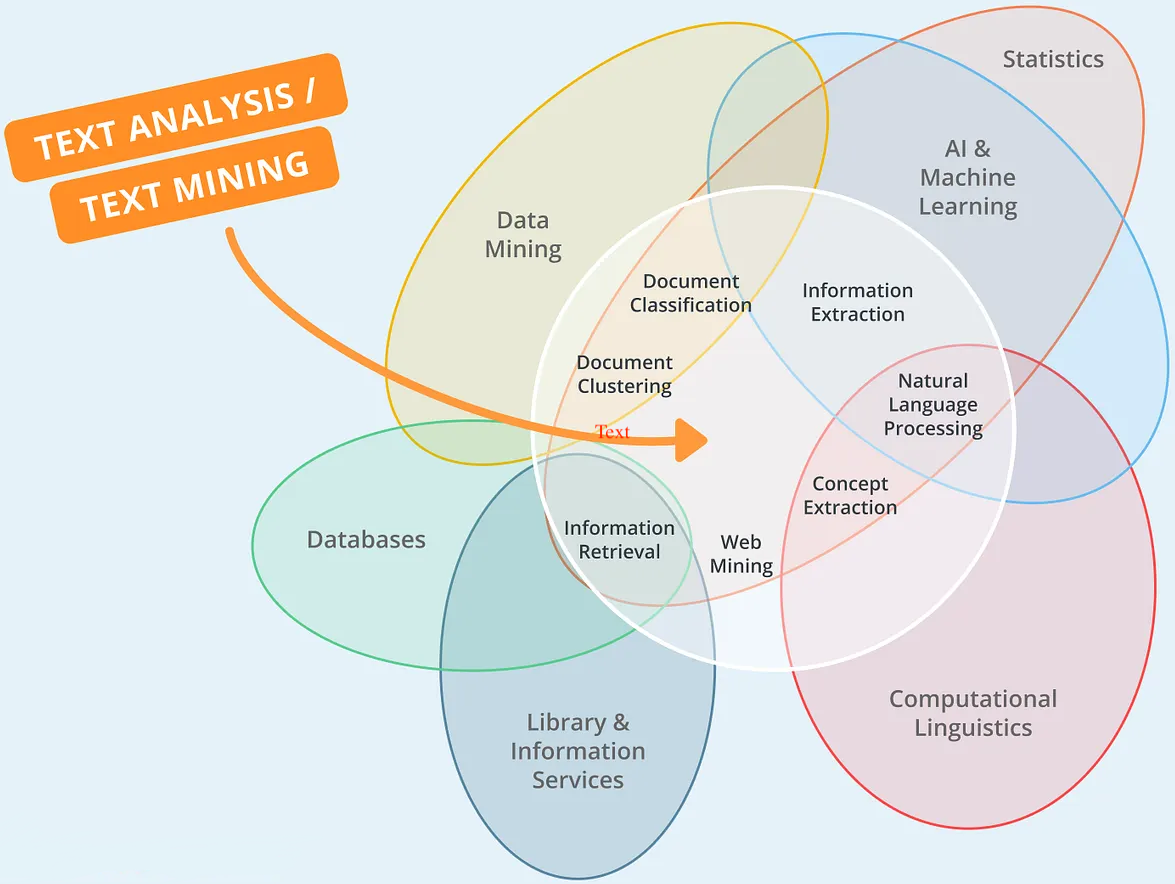
Enter NLP/Text Analytics
Text Analytics: a set of linguistic, analytical, and predictive technique to extract structure and meaning from unstructured documentsNLP: academic term for Text Analytics- analogous to “search” vs. “IR”
- Text Analytics ≈ NLP ≈ Text Mining
NLP Applications in Searching
- Word Prediction
- Assistive technologies (TextHelp)
- Google, Bing, Yahoo query suggestions
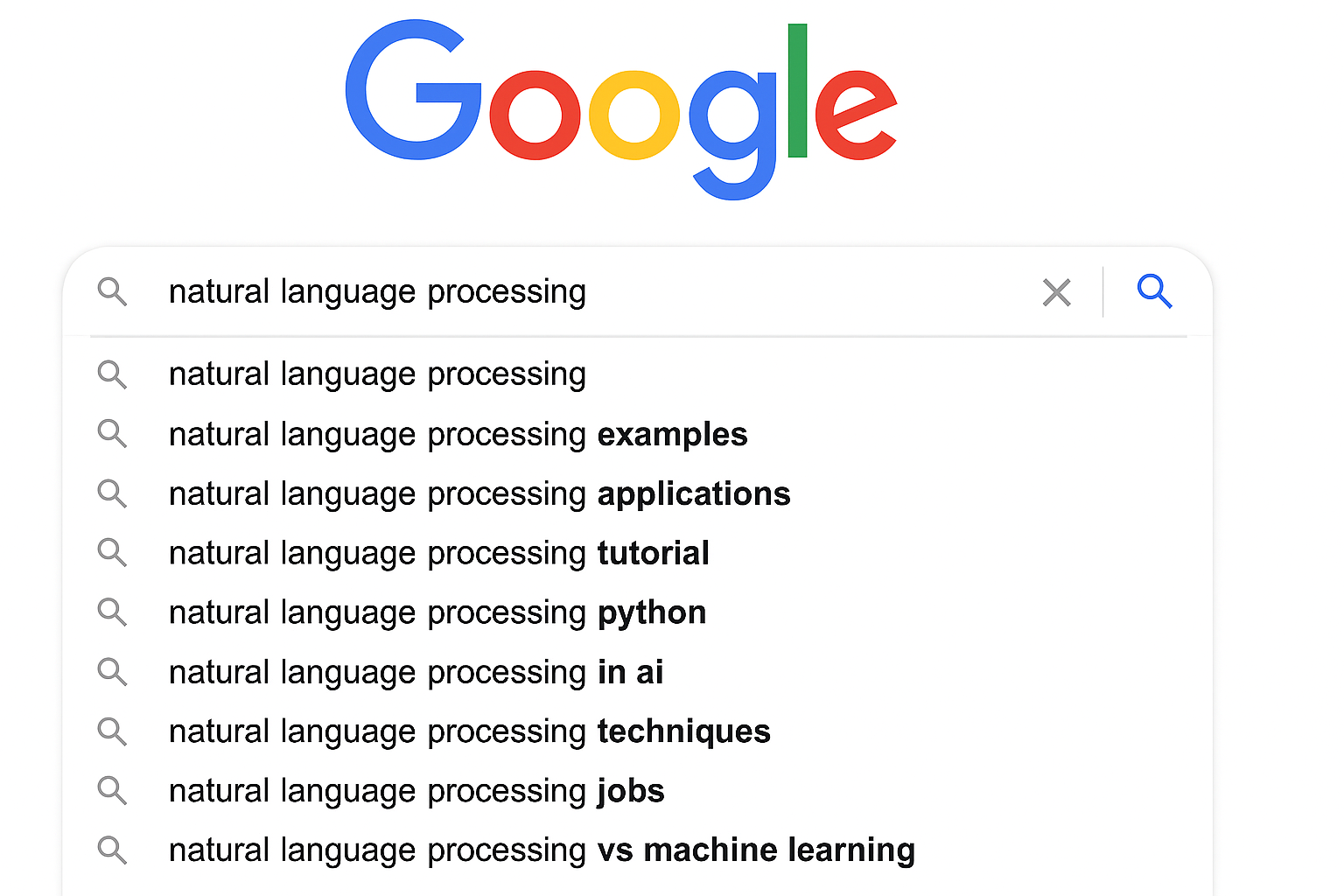
NLP Applications in Searching
- Spelling Correction
Autocorrect
![]()
Did you Mean
![]()
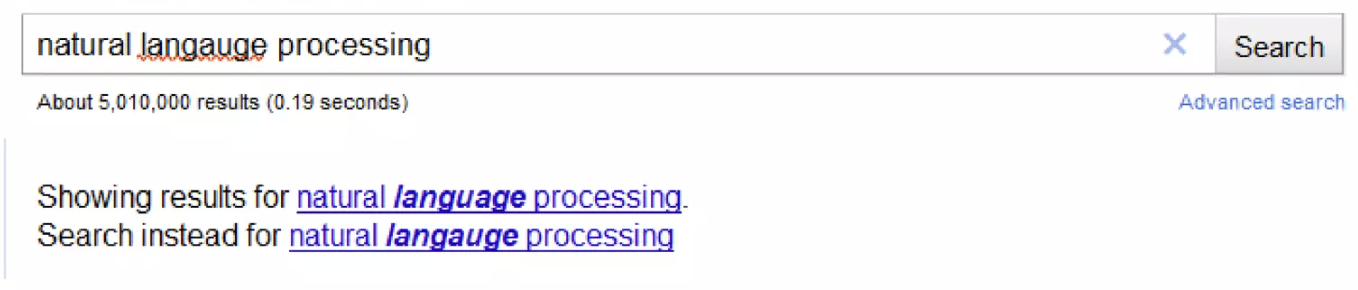

NLP Applications in Searching
Named Entity Recognition
- Identification of key concepts (eg. people, places, organizations)
- Increase precision of IR (New companies in New York vs. Companies in New York)
- Support navigation
- Improve machine translation
- Speech synthesis, auto-summarization, etc.

NLP Applications in Searching
- Information Extraction
- Identification of entities + relationships
- Based on pre-defined structures
- Can be used for metadata retrieval or store in database and query against it

Free Text Searching
Coversational Search
- Voice-based queries
- Chatbots in Libraries

Text Mining
Text mining is a process of automatically extracting information from the text with the aim of generating new knowledge
It is a specialized interdisciplinary field combining techniques from linguistics, computer science, and statistics to build tools that can efficiently retrieve and extract information from digital text
It assists in the automatic classification of documents
In text mining, “words are attributes or predictors and documents are cases or records, together these form a sample of data that can feed in well-known learning methods” (Weiss et al., 2005)
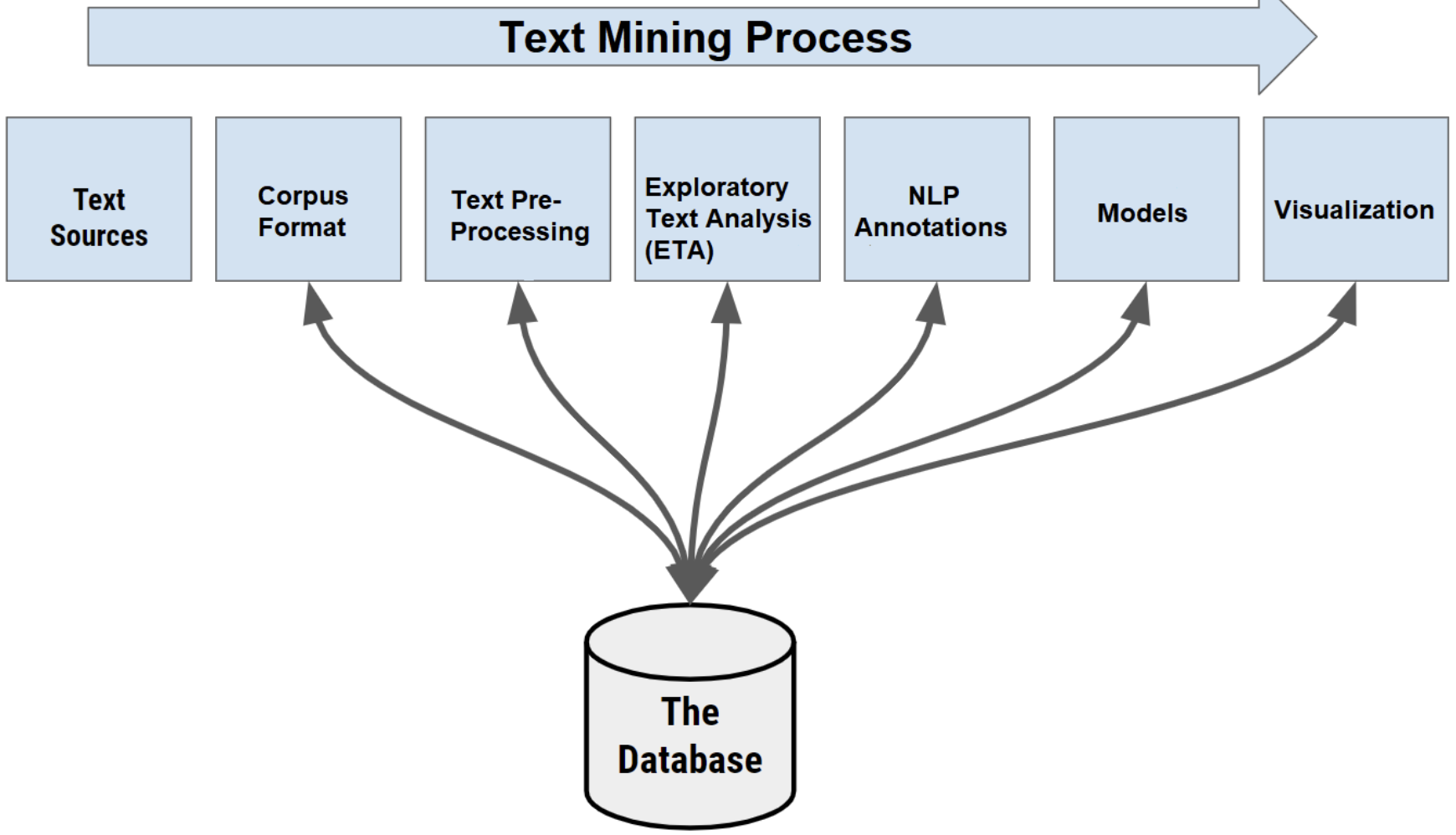
Brief History of Text Mining

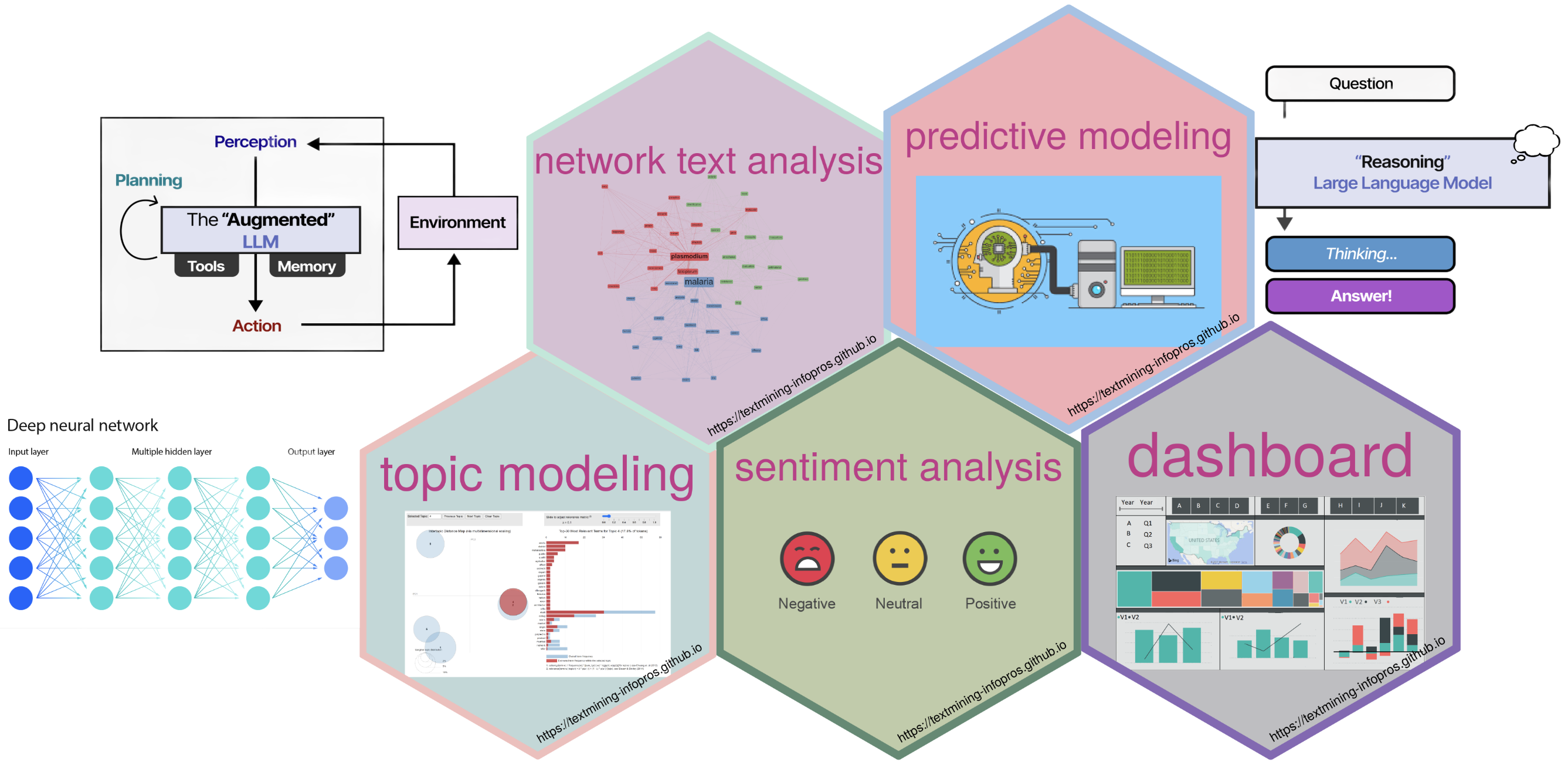
Different Text Mining Tasks
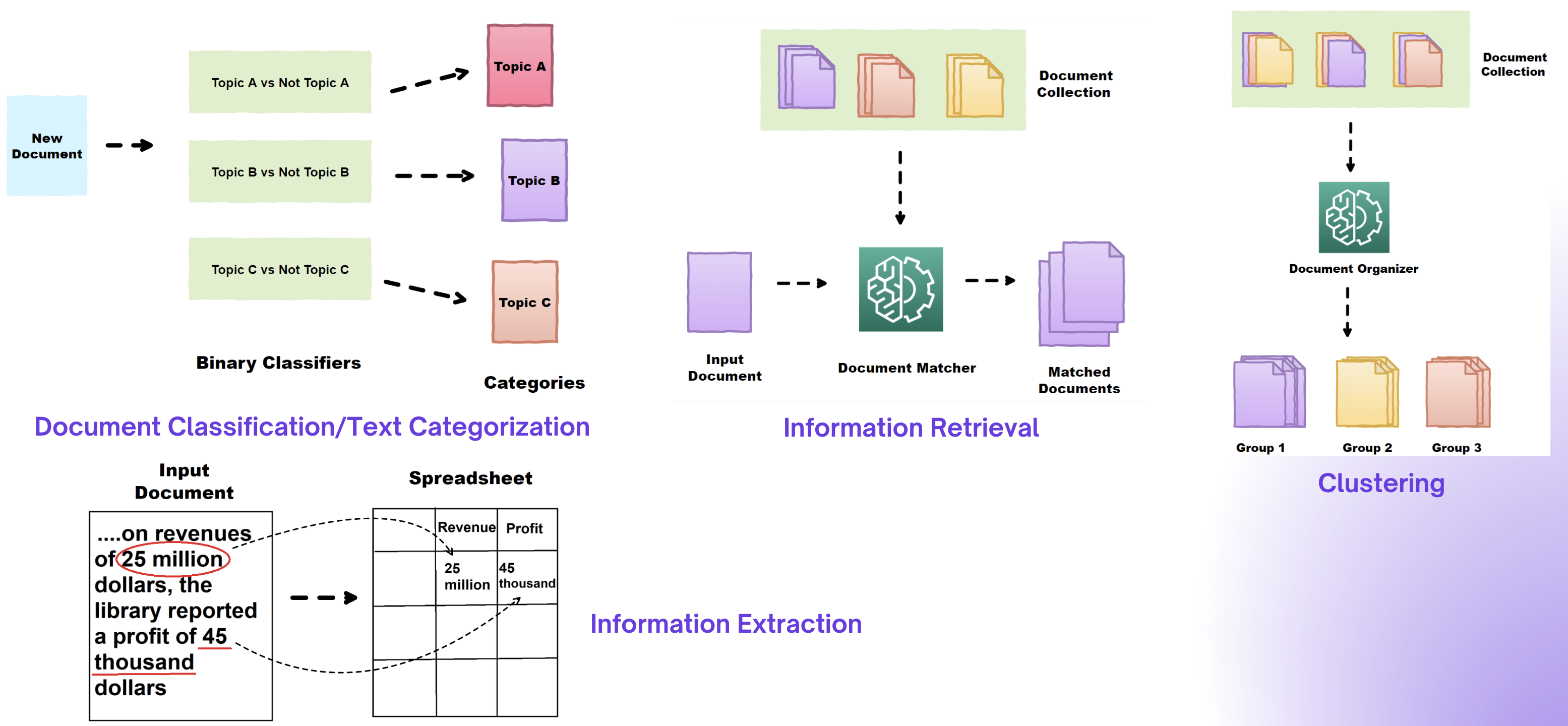
Advanced Text Mining Approaches