Acquiring Text
LIS 4/5693: Information Retrieval and Text Mining
Digital Trace Data
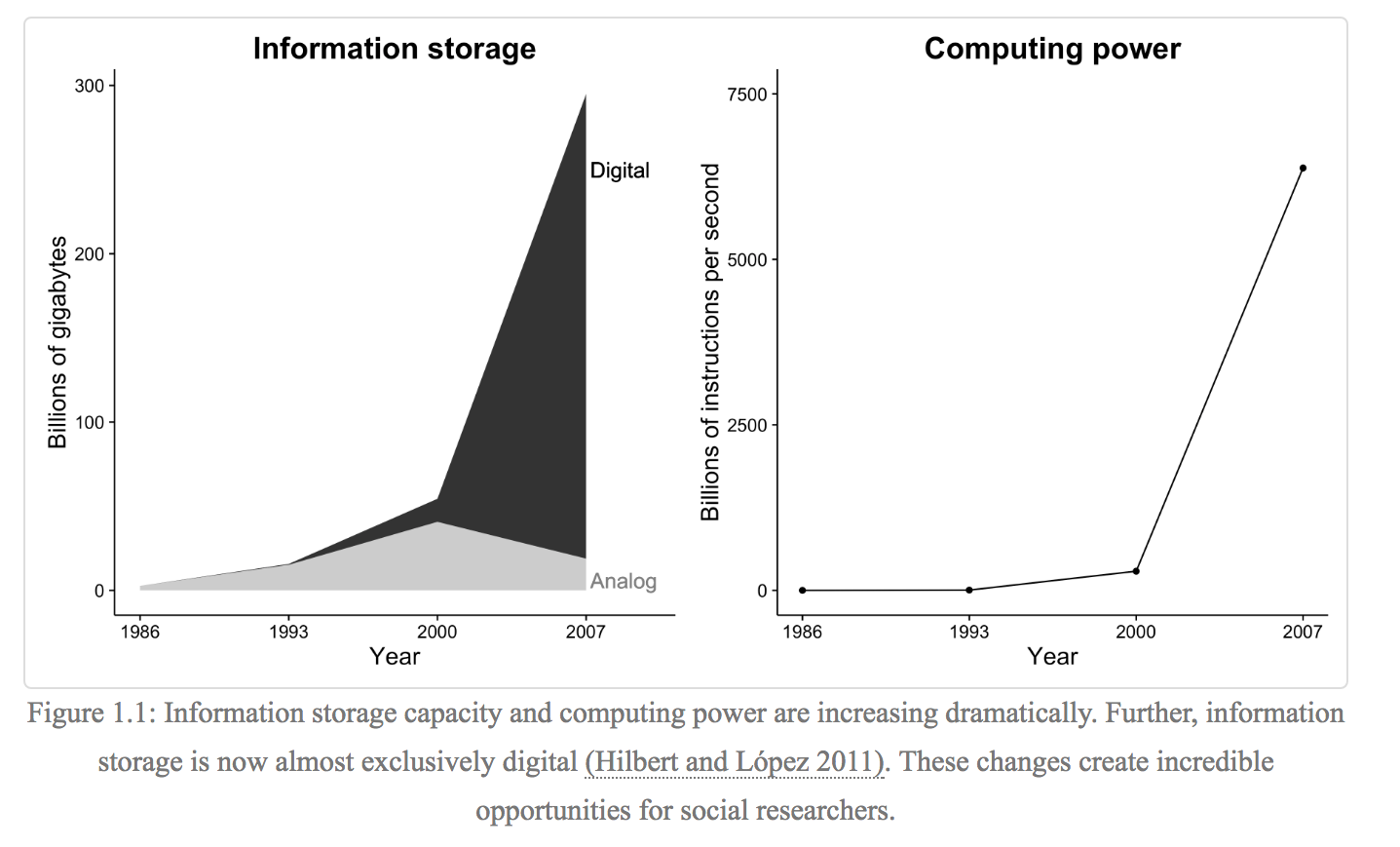
Strengths of Digital Trace Data
1. Always On

Strengths of Digital Trace Data (Cont.)
2. Non-Reactive
Strengths of Digital Trace Data (Cont.)
3. Captures Social relationships
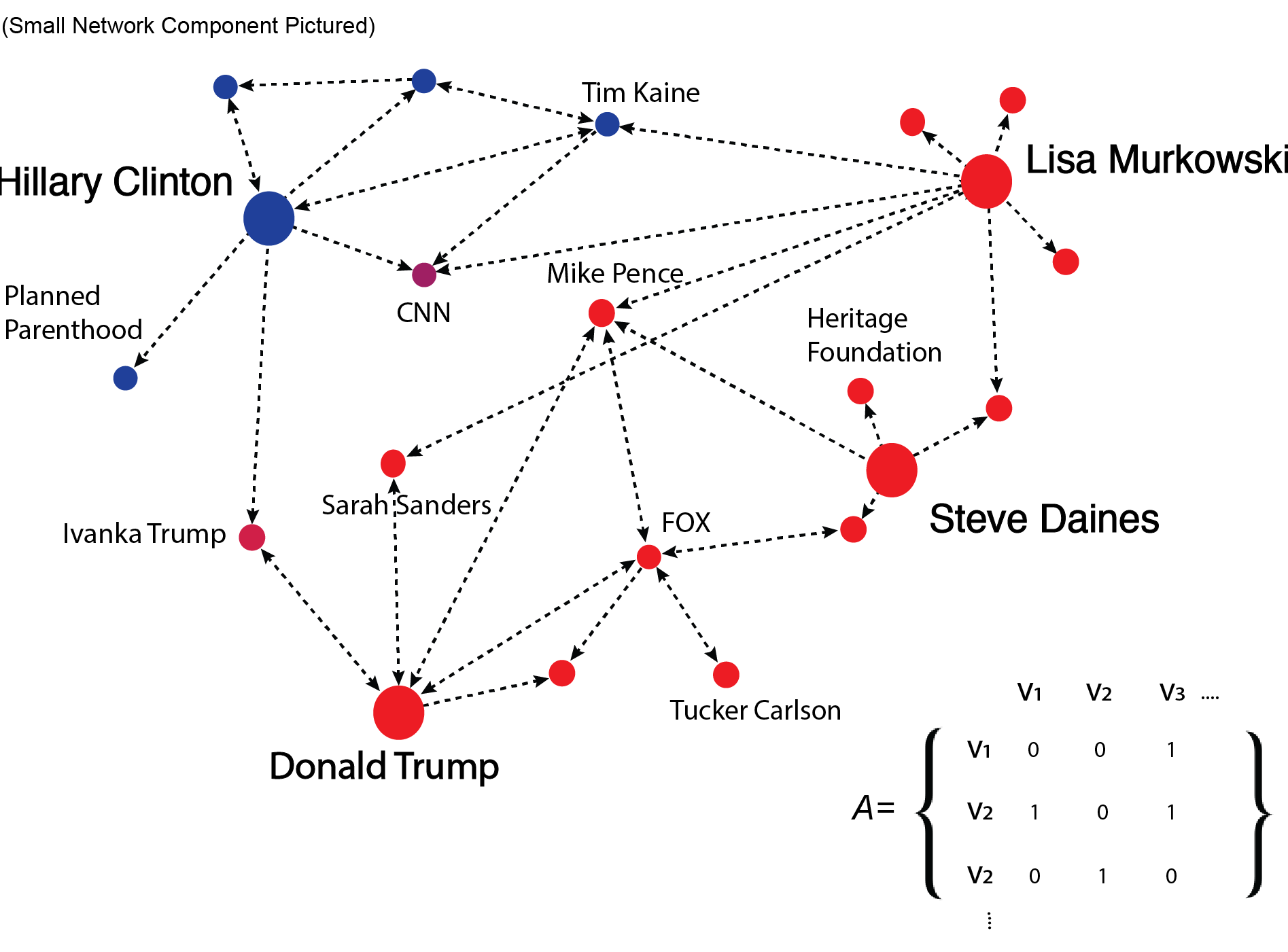
Weakness of Digital Trace Data
Despite the considerable advantages of digital trace data, they also create a range of challenges for empirical observation and causal inference
1. Inaccessible

Weakness of Digital Trace Data (Cont.)
2. Non-Representative
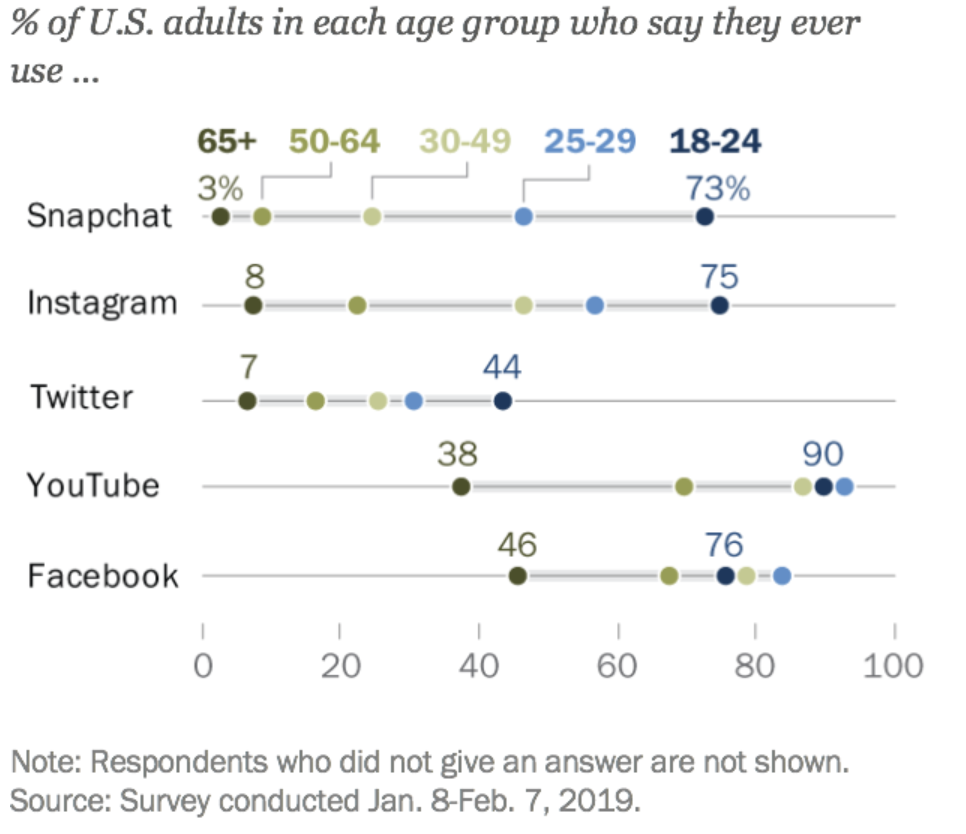
Weakness of Digital Trace Data (Cont.)
3. Drifting

Weakness of Digital Trace Data (Cont.)
4. Algorithmic Counfounding
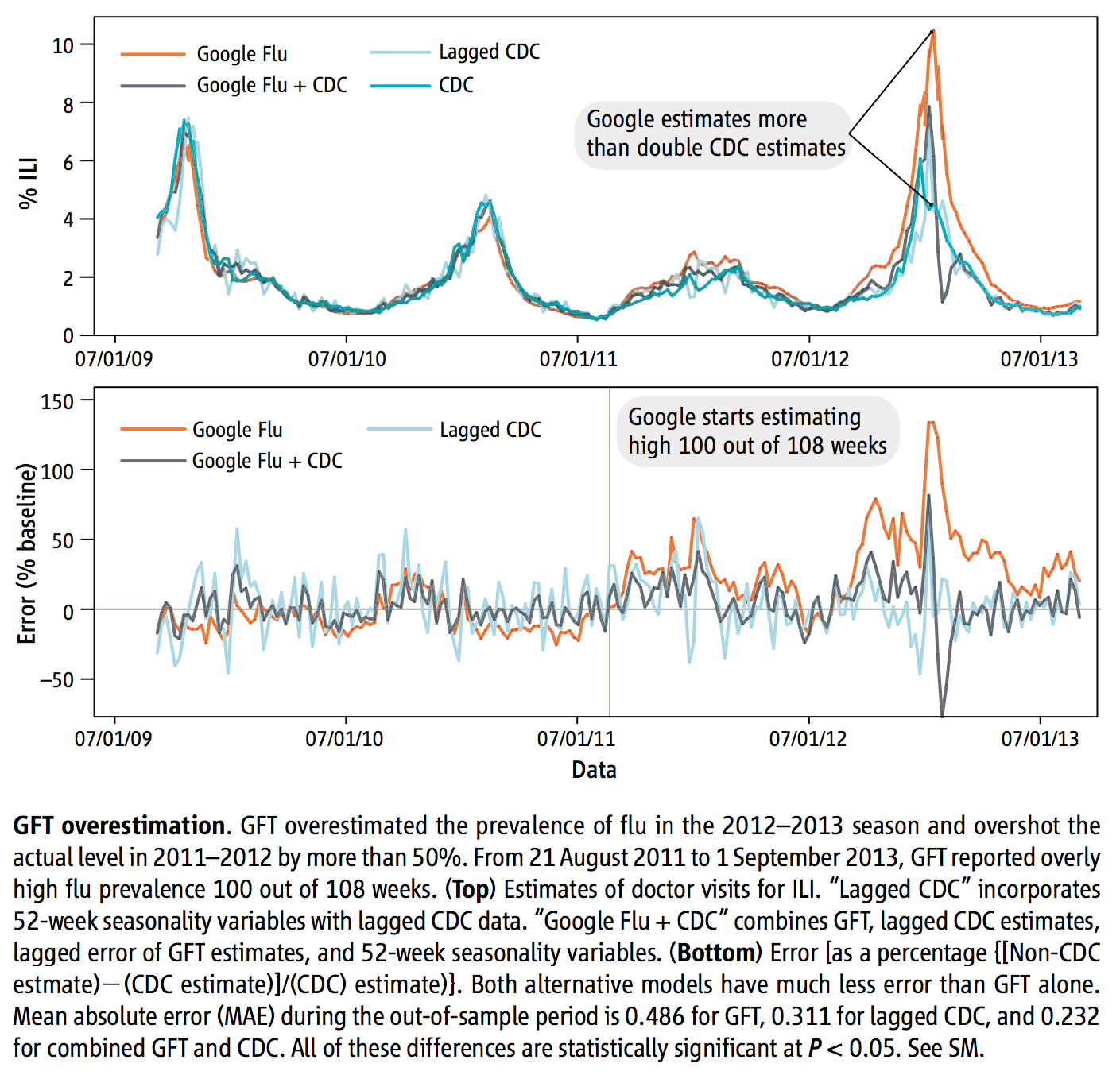
Weakness of Digital Trace Data (Cont.)
5. Unstructured

Weakness of Digital Trace Data (Cont.)
6.Sensitive

Weakness of Digital Trace Data (Cont.)
7. Incomplete
Weakness of Digital Trace Data (Cont.)
8.Elite Bias
You know the famous saying, “history is written by the victors”? Much digital trace data is also created by people who are elites, and who might provide selective or incomplete accounts of what is going on, or worse.
9. Positivity-Bias
Finally, digital trace data often have performative dimensions. Many people do not report negative information about themselves online precisely because they know that their friends, colleagues – or other people they do not know – may be watching them. This creates another common form of bias in social media research.

Future of Digital Trace Data
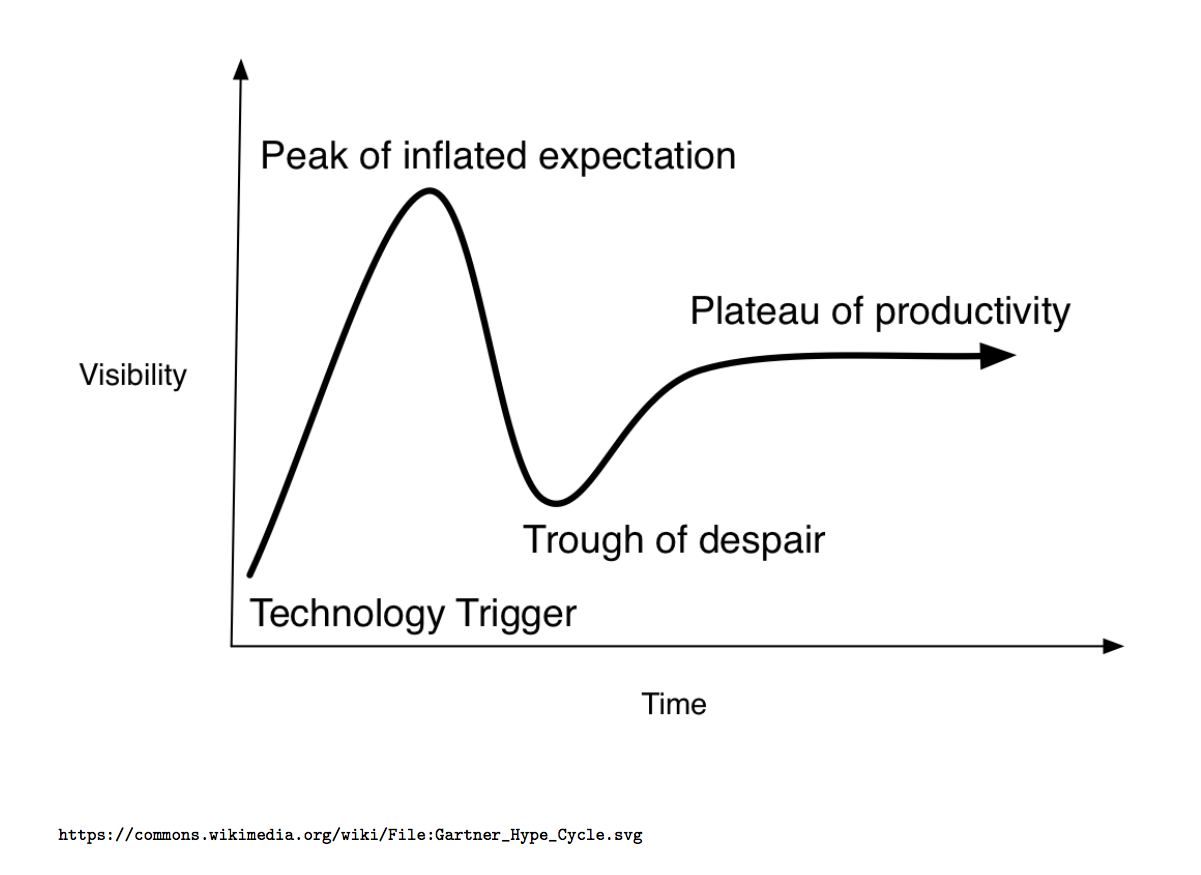
We are Data
We are filled with data in today’s networked society
through our web activity, we are assigned gender, ethnicity, class, age, education level, and potential status of parent with x no. of children (digital trace data/digital footprint/digital breadcrumbs)
if internet metadata identifies a user as foreigner than they lose right to privacy afforded to U.S. citizens
who would have thought that class status, citizenship, ethnicity could be algorithmically understood?

Algorithmic Confounding/Biasness
It occurs when a computer system reflects the implicit values of the humans who are involved in collecting, selecting, or using data
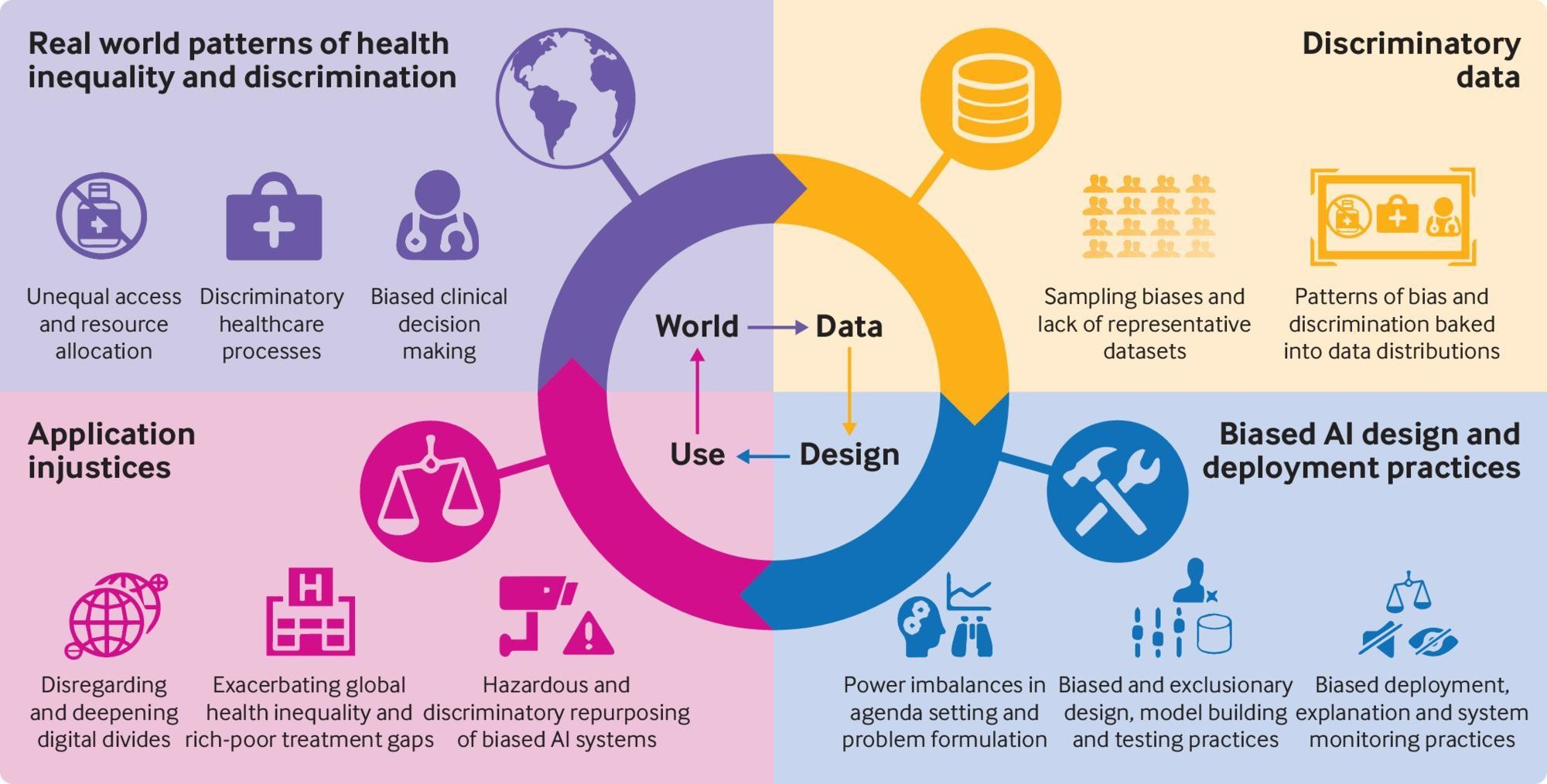
Forms of Data
A small list of open multimedia formats. For a list of file formats, consider checking out the Library of Congress’ list of Sustainability of Digital Formats.
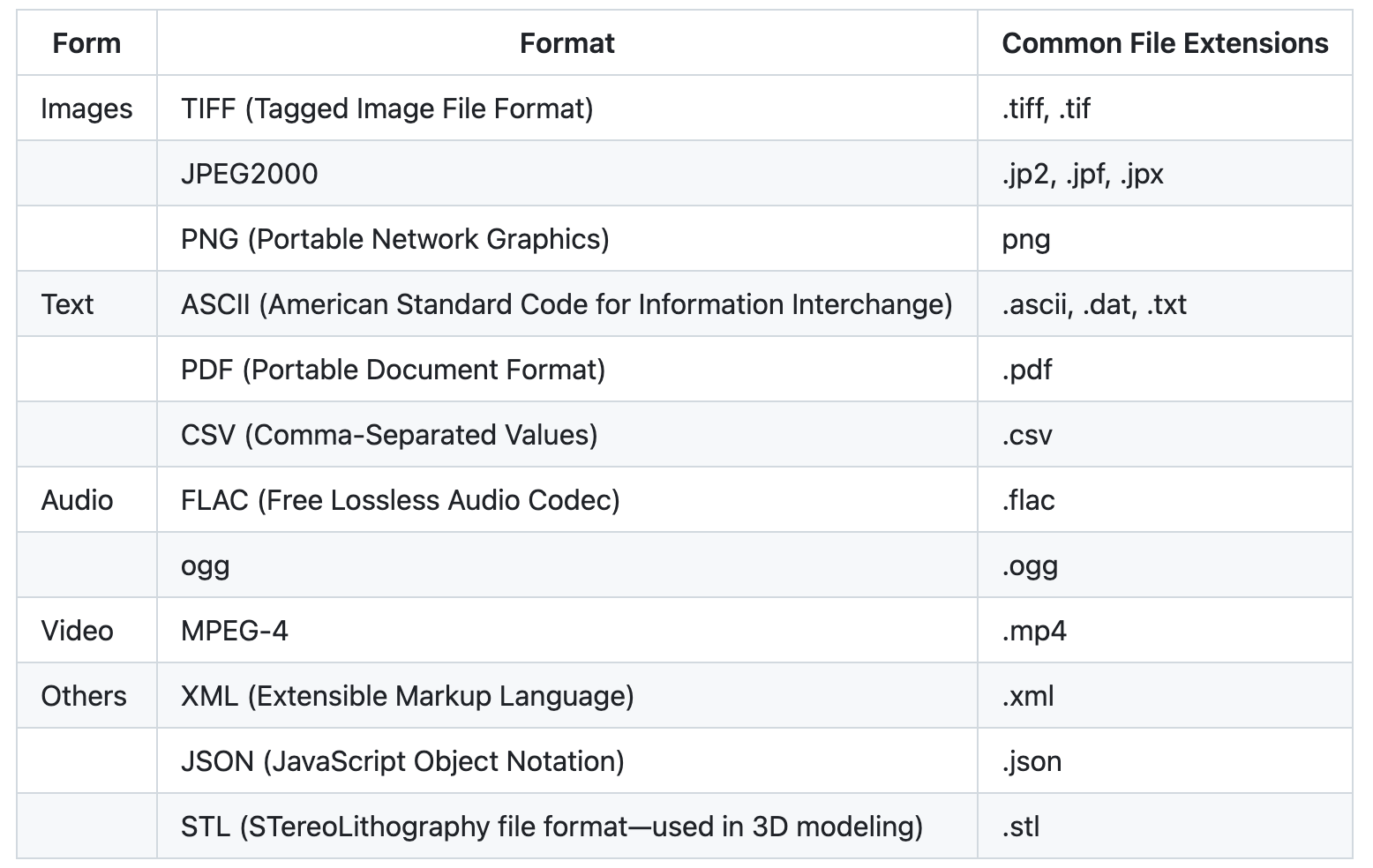
Importance of Using Open Data Formats
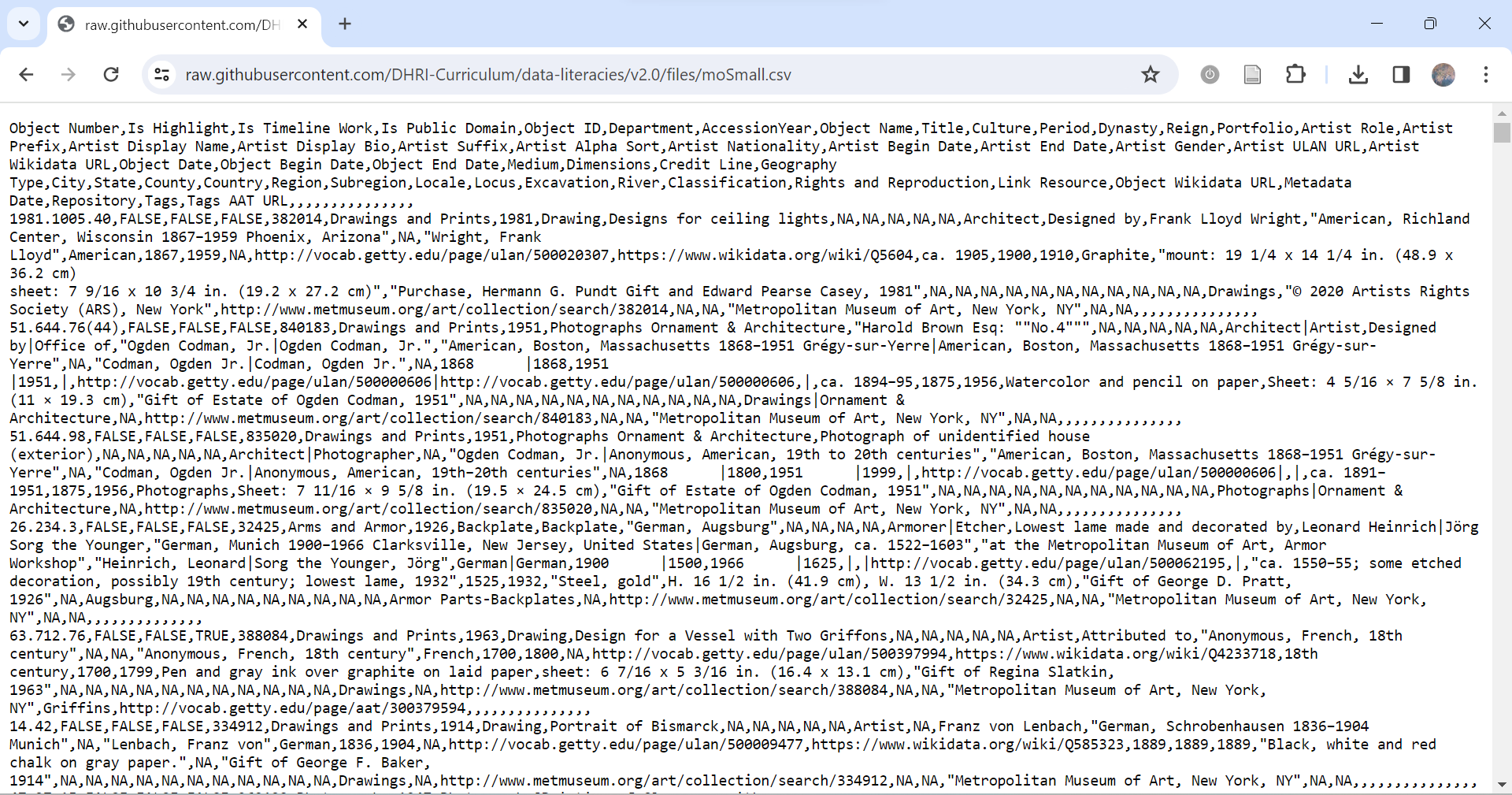
A screenshot of a dataset as a cvs file, uncompressed, and follow an open standard
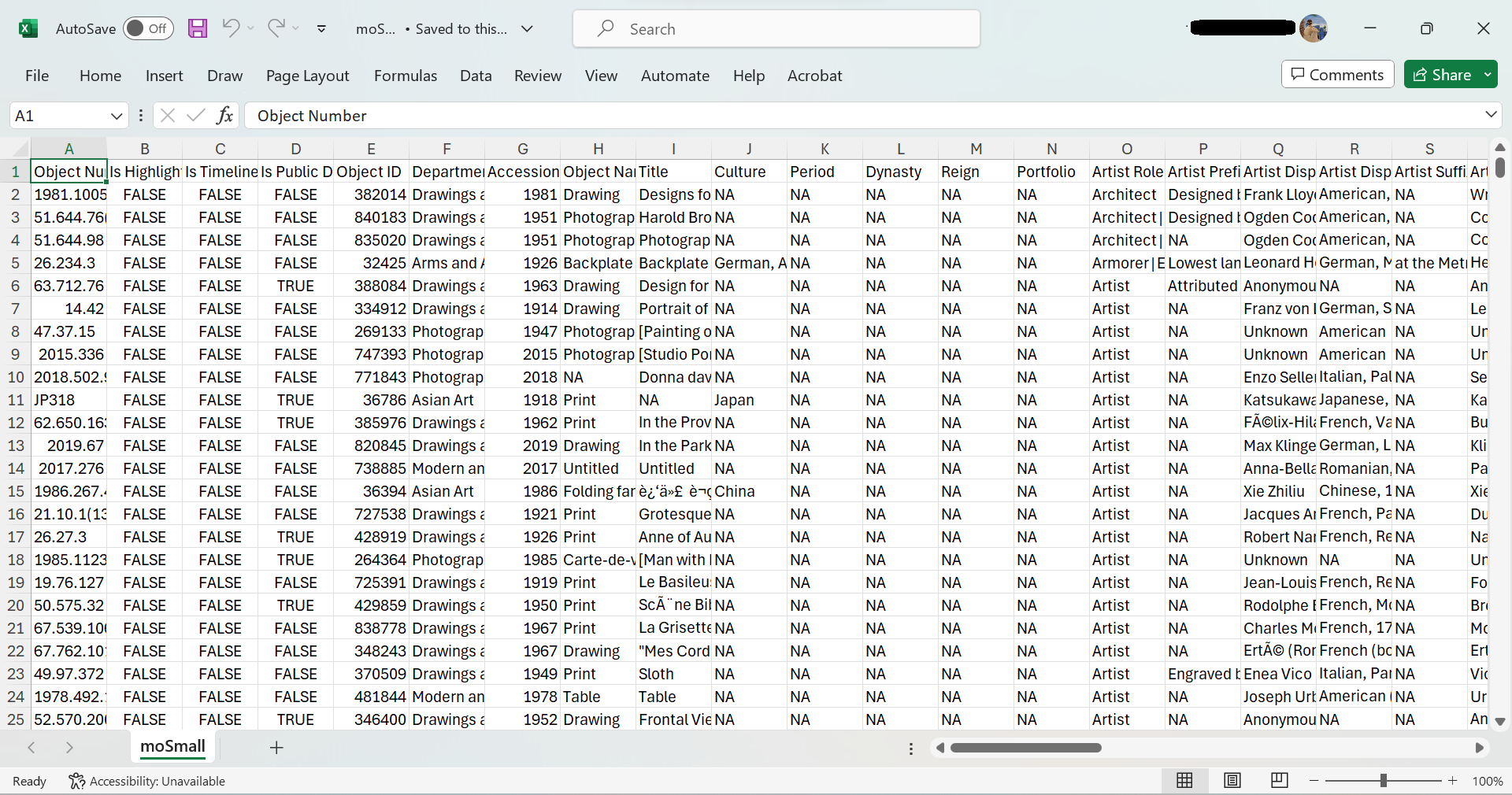
A screenshot of the same dataset in an Excel file (.xlsx). Unlike the previous image, this is a proprietary format
Challenge: Forms of Data
As you inspect the information present in each image, consider these questions:
What are some forms of data used in the project?What are some forms of data outputted by the project?Where was the data retrieved from to complete the project?
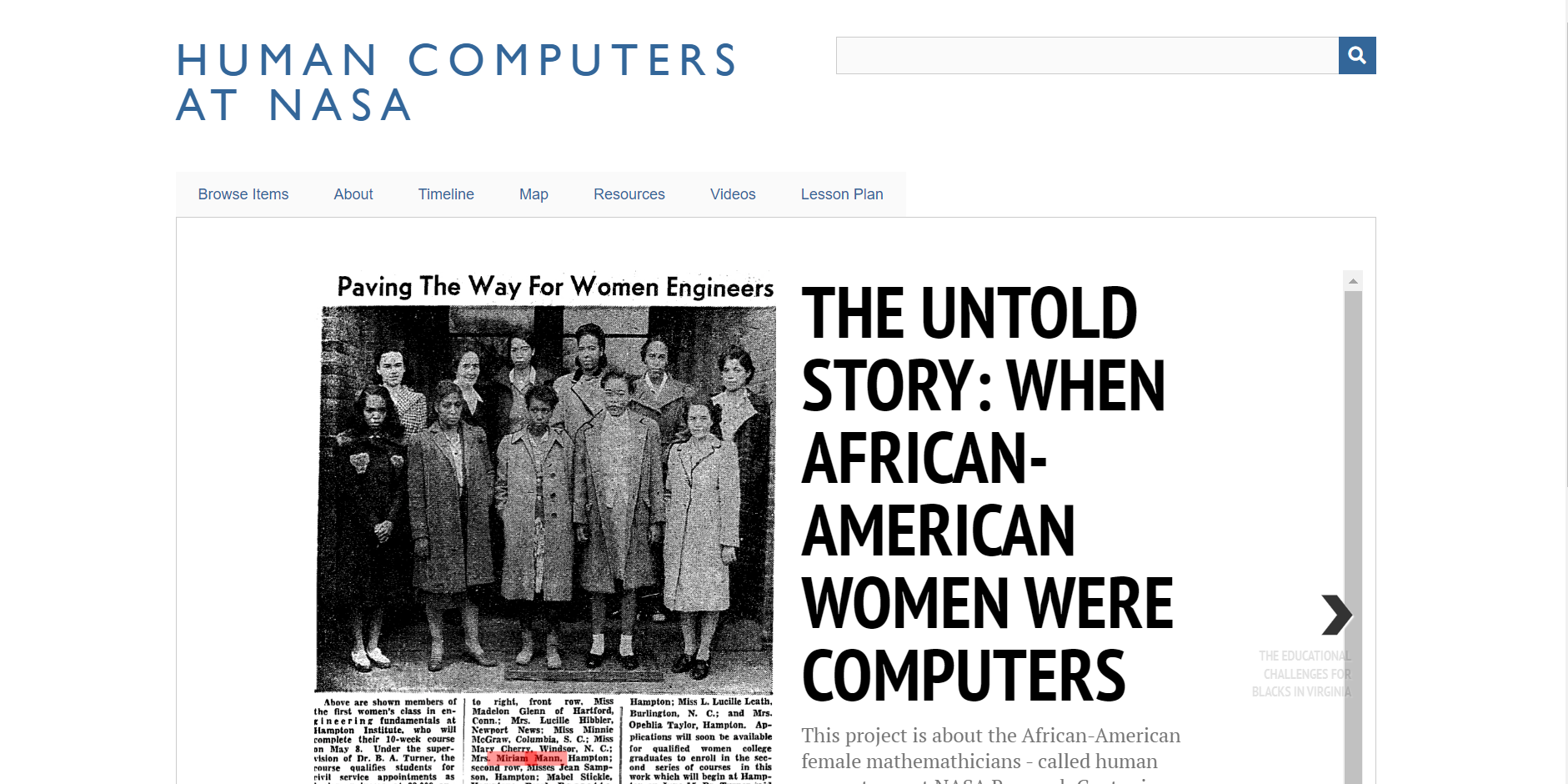
Human Computers at NASA is an archival project that “seeks to shed light on the buried stories of African American women with math and science degrees who began working at NACA (now NASA) in 1943 in secret, segregated facilities.”

Listen for the Iraqis in NYC! is an audio community mapping project that seeks to locate the Iraqi population in NYC using their own voices.
Stages of Data
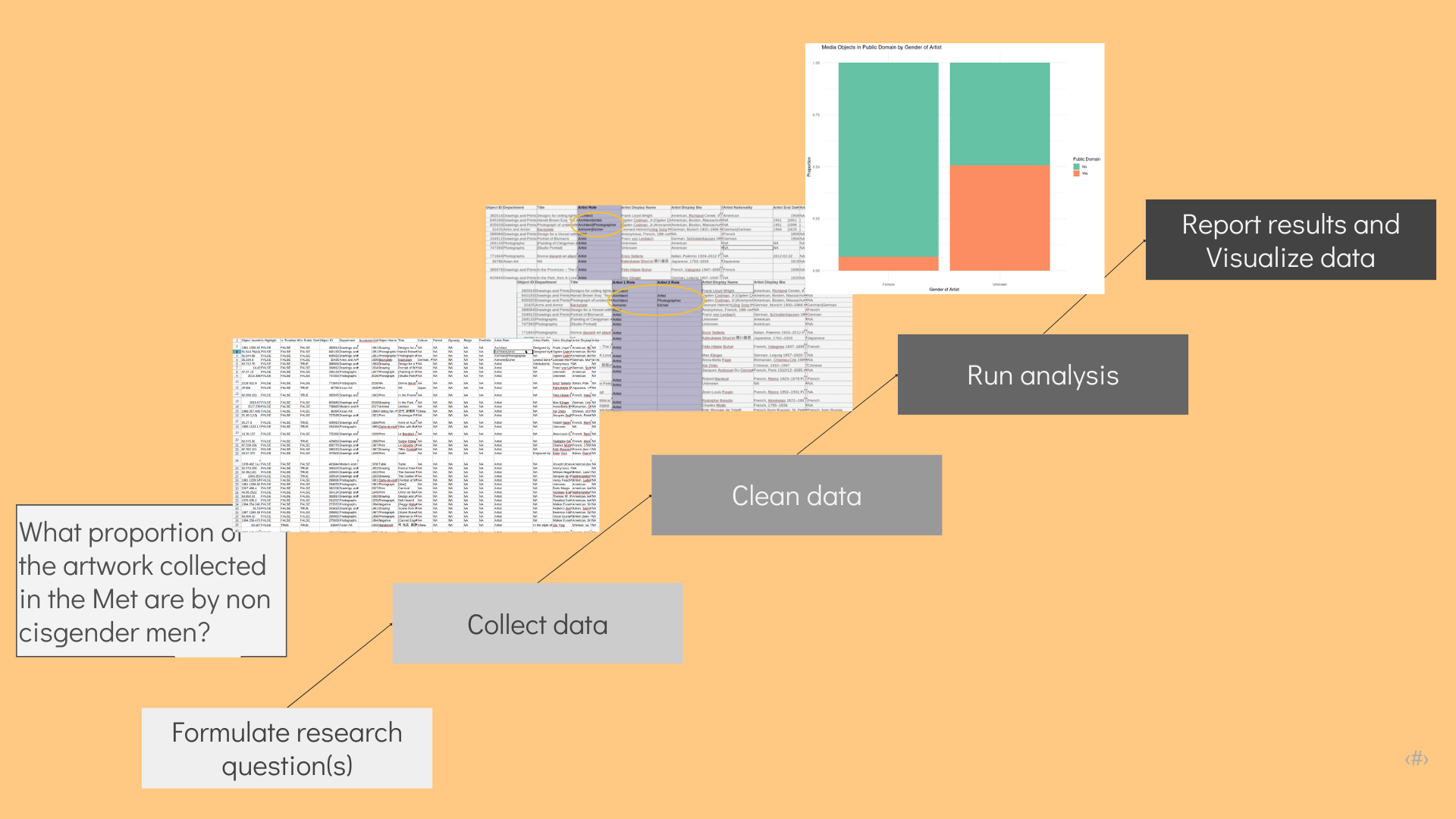
Stages of Data: Non-Linear
Different Ways to Get Data
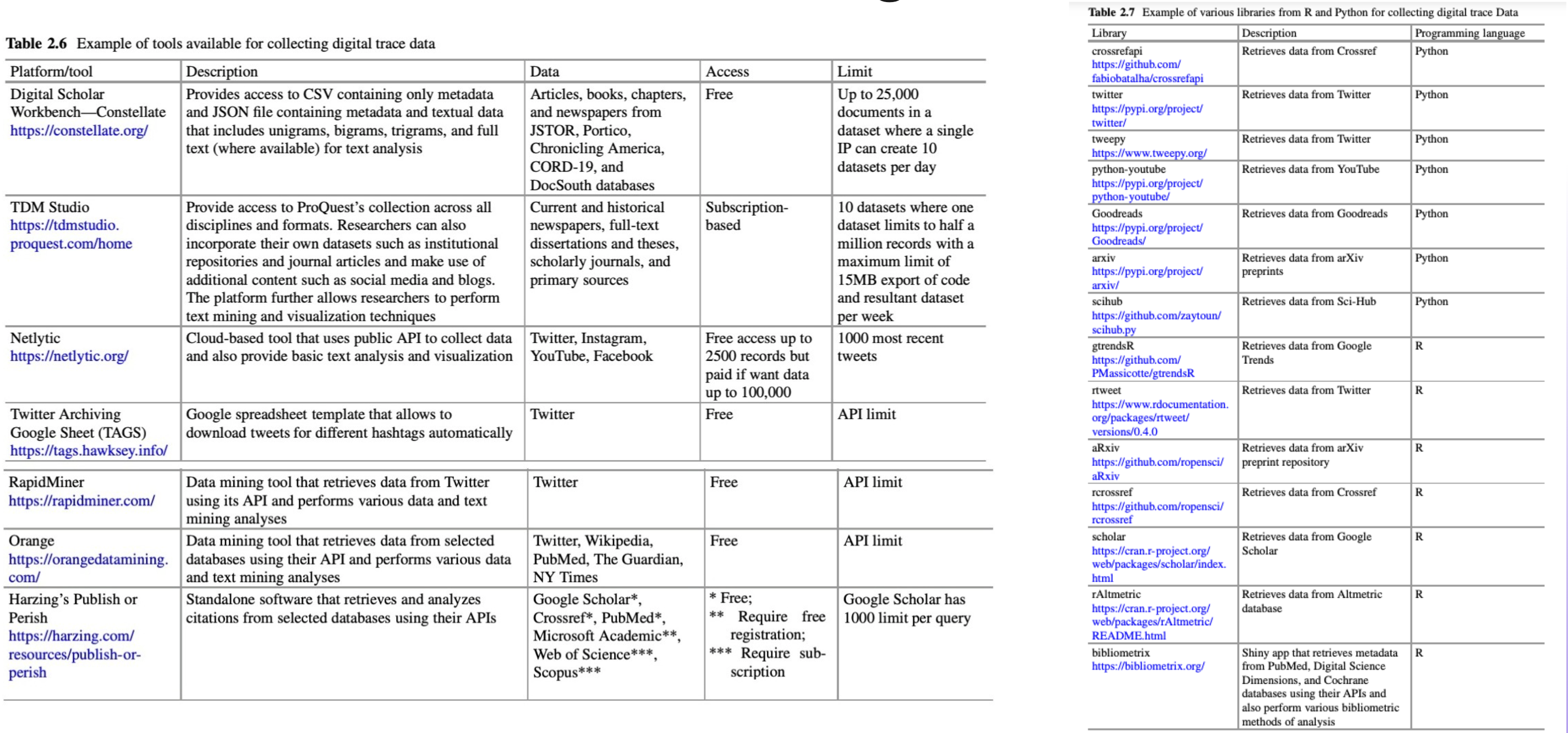
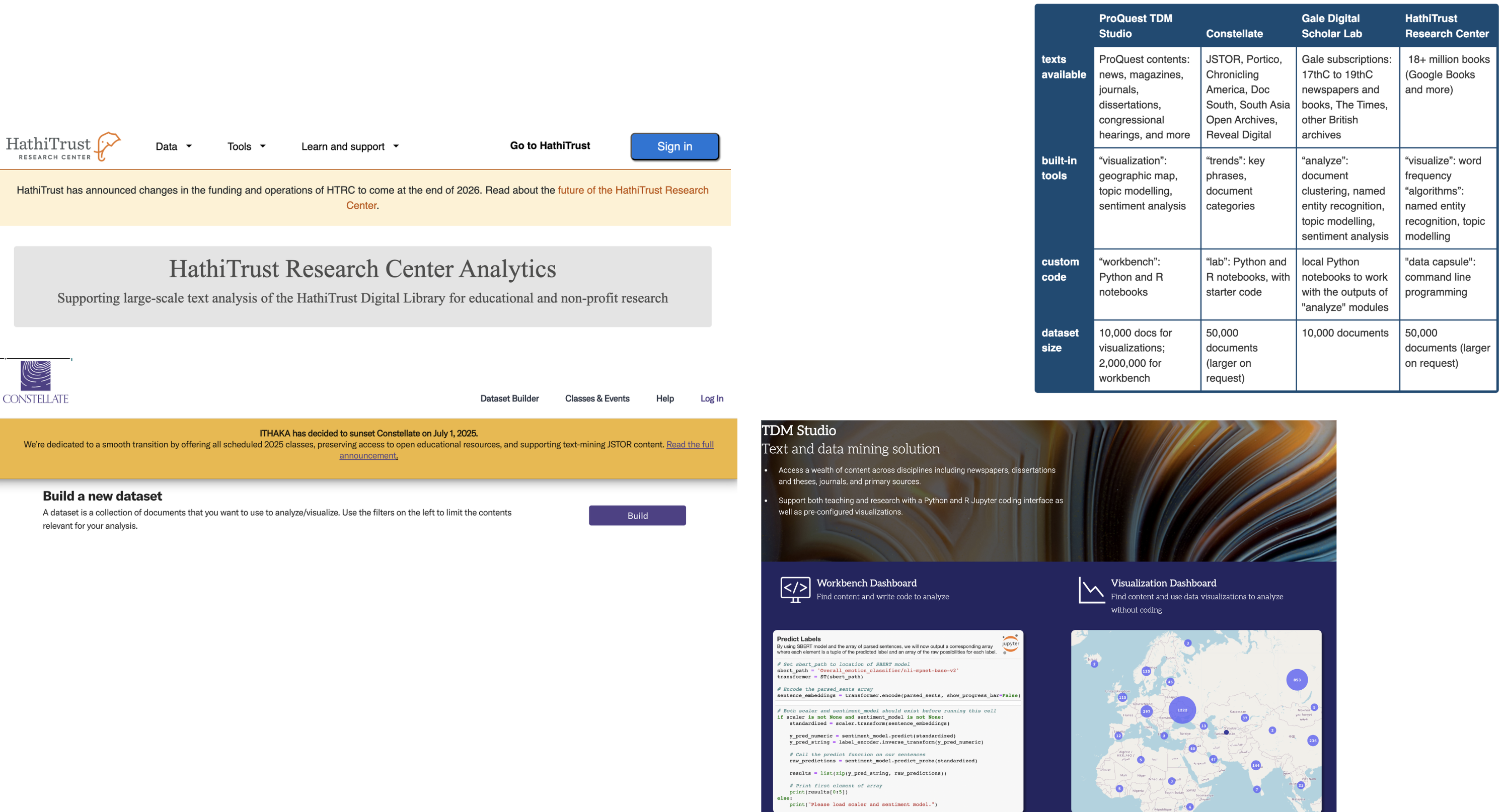
Text Mining Platforms
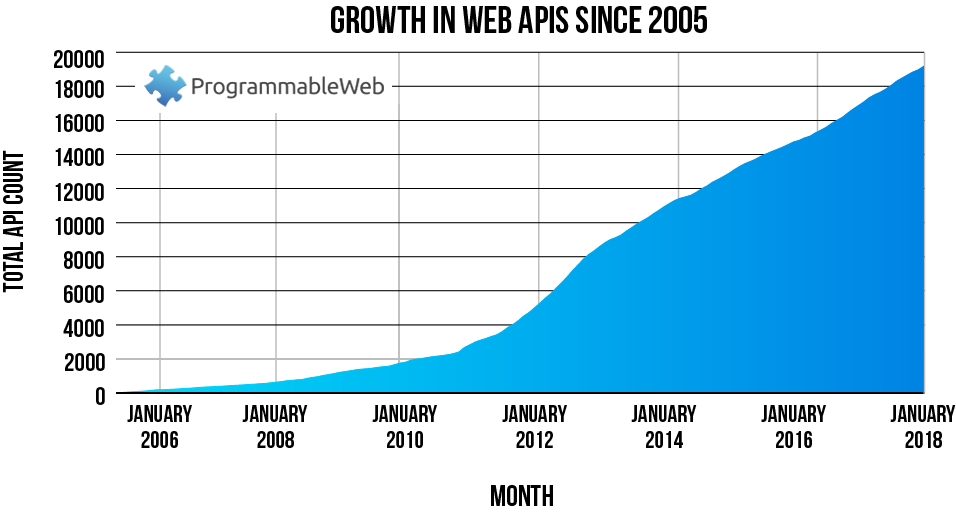
What is an Application Programming Interface?
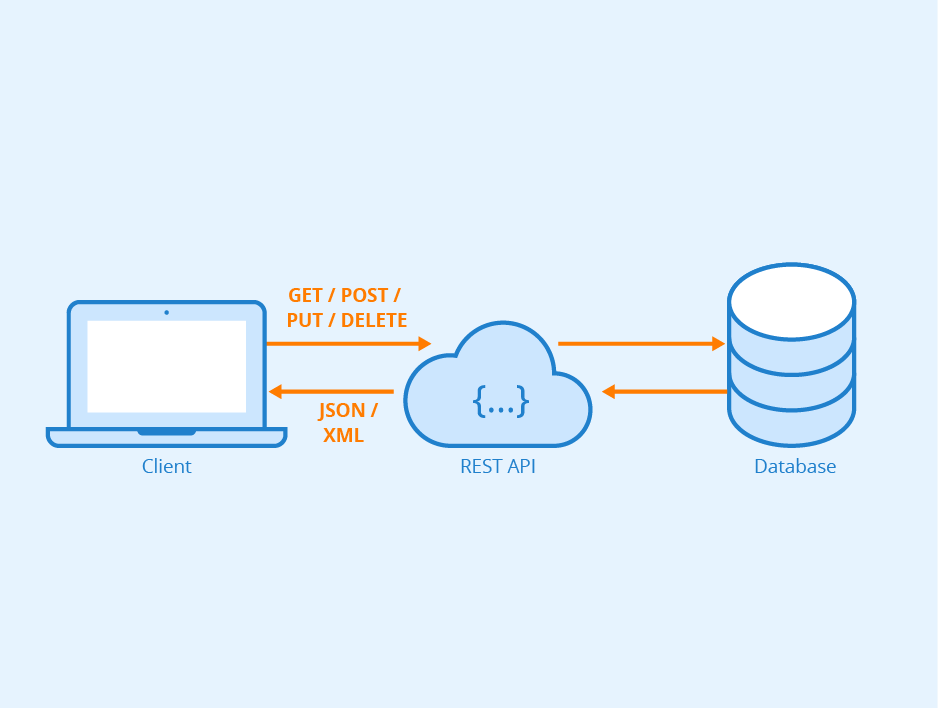
How Does an API Work?
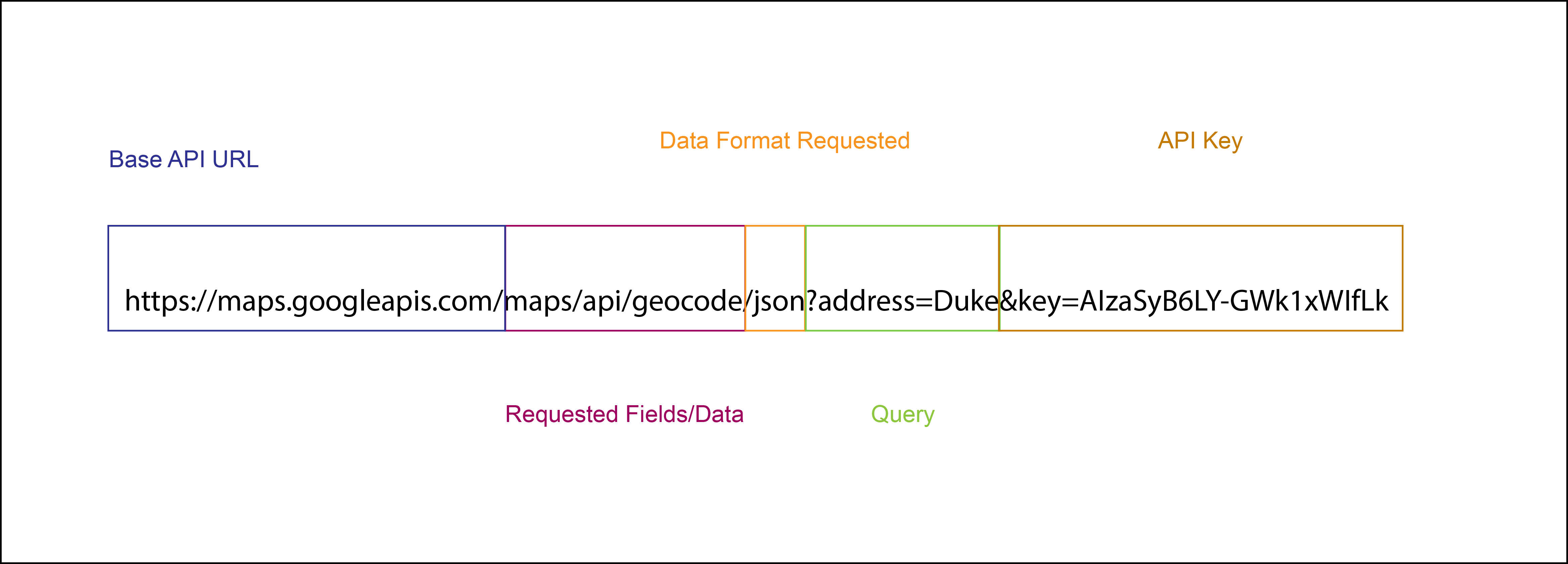
Output of API Call

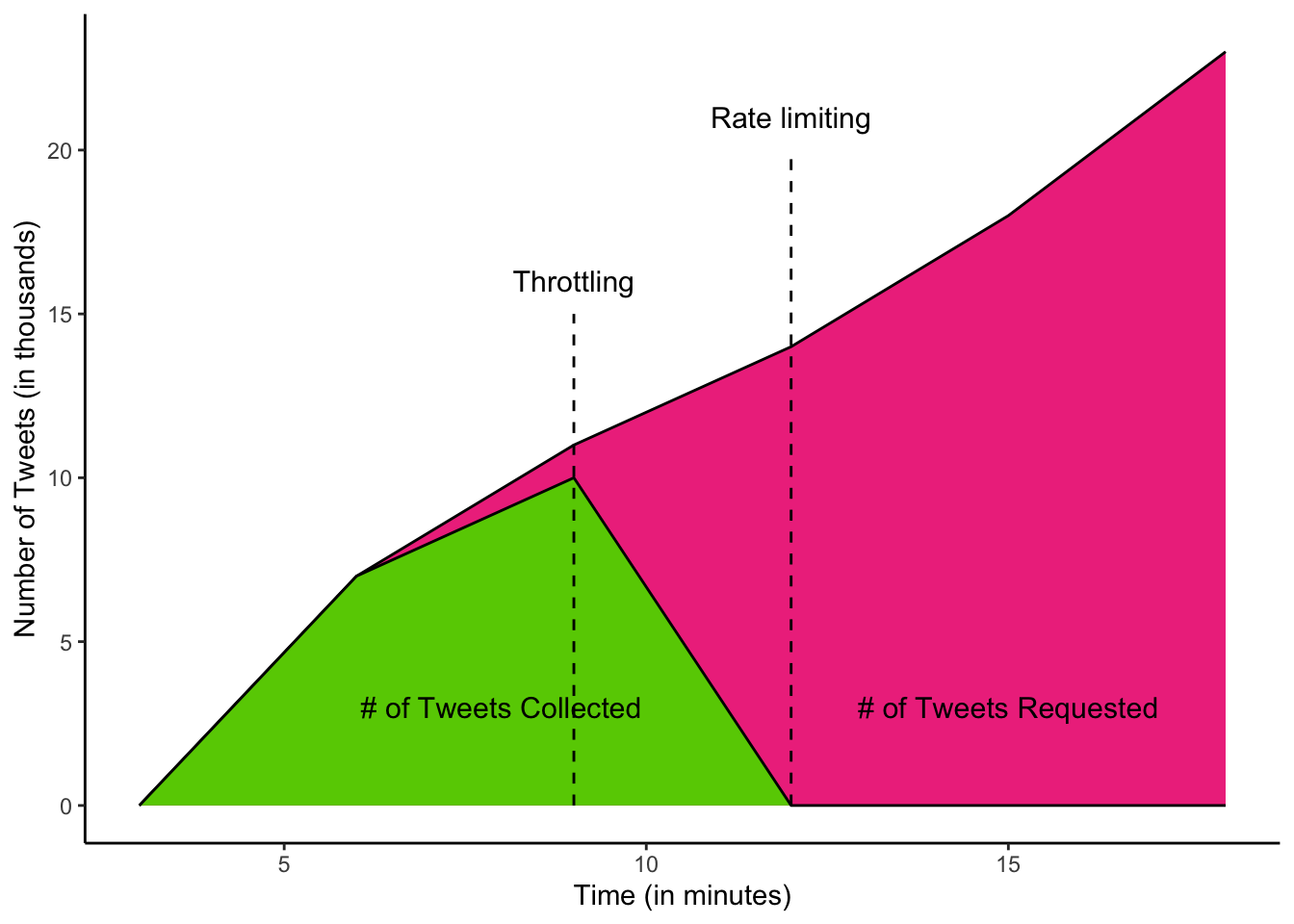
Rate Limiting
Screen-Scraping or Web Scraping

So… When Should I Use Screen-Scraping?
