Corpus Building and Representation
LIS 4/5693: Information Retrieval and Text Mining
Introduction
What is a Corpus?
- Corpus (pl. corpora) = ‘body’
- Collection of written text or transcribed speech
- Usually but not necessarily purposefully collected
- Usually but not necessarily structured
- Usually but not necessarily annotated
- Usually stored on and accessible via computer
- Corpus ~ text archive
Representativeness
A corpus can be a collection of (1)
machine-readable(2)authentictexts (including transcripts of spoken data) which is (3)sampledto be (4)representativeof a particular language or task
- A corpus is different from a random collection of texts or an archive
Representativenessis a defining feature of a corpus- As language is infinite but a corpus has to be finite in size, we sample and proportionally include a wide range of text types to ensure maximum balance and representativeness
Some Definitions: Corpus
- “generally
assembled with particular purposes in mind, and are often assembled to be (informally speaking) *representative*of some language or text type” (Leech 1992: 116) - “…selected and ordered according to
explicit linguistic criteriain order to be used as a sample of the language” (Sinclair 1996) - “A
well-organizedcollection of data” (McEnery 2003) - “gathered according to
explicit design criteria” (Tognini-Bonelili 2001: 2) - “built according to
explicit design criteria for a specific purpose” (Atkins et al 1992) texts selected and put together“in a principled way”(Johansson 1998: 3)
What is Representativeness?
A corpus is thought to be representative of the language variety it is supposed to represent (Leech 1991)
Representativeness refers to the extent to which a
sampleincludes the full range ofvariabilityin apopulation(Biber 1993)
- Representativeness is a fluid concept closely related to your research questions
Two Types of Representativeness
The representativeness of general corpora and specialized corpora (domain/genre specific) are achieved and measured in different ways
- General corpora
- Balance: Range of genres included in a corpus and their proportion
- Sampling: How the text chunks for each genre are selected
- Specialized corpora
- Degree of closure/saturation: Closure/saturation for a particular linguistic feature of a variety of language
Why Should We Care about Representativeness?
- Corpus-based studies
- Interpret results of corpus research
- Corpus user
- Important to “know your corpus”
- Decide whether a given corpus is appropriate for specific research question
- Make appropriate claims on the basis of such corpus
- Corpus creator
- Make corpus as representative as possible of a language (variety) claimed to represent
- Document design criteria explicitly and make documentation available to corpus users
Criteria for Text Selection
- The criteria used to select texts for a corpus are principally
external- The external vs. internal criteria corresponds to Biber’s (1993:243)
situational vs. linguistic perspectivesExternal criteriaare defined situationally irrespective of the distribution of linguistic featuresInternal criteriaare defined linguistically, taking into account the distribution of such features
- The external vs. internal criteria corresponds to Biber’s (1993:243)
- It is
circularto use internal criteria like the distribution of words or grammatical features as the primary parameters for the selection of corpus data
Criteria for Text Selection
Time? If a corpus is not regularly updated, it rapidly becomes unrepresentative (Hunston, 2002)
Relevance of permanence in corpus design actually depends on how we view a corpus - a static or dynamic language model
Static model: sample corpora (nearly all existing corpora)Dynamic model: monitor corpora
Criteria for determining the structure of a corpus should be small in number, clearly separate from each other, and efficient as a group in delineating a corpus that is representative of the language or variety under examination (Sinclair, 2005)
Corpus Balance
- A balanced corpus covers a wide range of text categories which are supposed to be representative of the language (variety) under consideration
- The proportions of different kinds of text it contains should correspond with informed and intuitive judgements
- There is no scientific measure for balance – just best estimation
The acceptable balance is determined by the intended use – your research questions
Pragmatics in Corpus Design
Most general corpora of today are badly balanced because they do not have nearly enough spoken language in them (Sinclair, 2005)
- Pragmatic considerations also mean that balance is a more important issue for a static sample corpus than for a dynamic monitor corpus
- As a monitor corpus is frequently updated, it is usually “impossible to maintain a corpus that also includes text of many different types, as some of them are just too expensive or time consuming to collect on a regular basis” (Hunston, 2002: 30-31)
Corpus Balance: Some Tips
The corpus builder should retain, as target notions, representativeness and balance. While these are not precisely definable and attainable goals, they must be used to guide the design of a corpus and the selection of its components (Sinclair, 2005)
It would be short-sighted indeed to wait until one can scientifically balance a corpus before starting to use one, and hasty to dismiss the results of corpus analysis as ‘unreliable’ or ‘irrelevant’ because the corpus used cannot be proved to be ‘balanced’ (Atkins et al, 1992: 6)
Sampling: Corpus Creation
Language is infinite, but a corpus is finite in size, so sampling is inescapable in corpus building
Population ( language/variety) vs. sample (corpus)
- A sample is a scaled-down version of a larger population
- A sample is representative if what we find for the sample also holds for the general population
Corpus representativeness and balance rely heavily on sampling
- A corpus is a sample of a given population (language or language variety)
Sampling: Corpus Creation
- Sampling unit
- For written text, it could be a book (chapter), periodical or newspaper (article)
- Sampling frame
- A list of sampling units
- Populations
- Assembly of all sampling units, which can be defined in terms of
- Language production (demographic: speakers and writers)
- Language reception (demographic: audience and readers)
- Language as a product (registers and genres)
- Assembly of all sampling units, which can be defined in terms of
Size of Samples: Corpus Creation
Full texts or text segments?
Samples of language for a corpus should wherever possible consist of entire documents or transcriptions of complete speech events (Sinclair 2005)
|--> Good for studying textual organizationA full-text corpus may be inappropriate or problematic
- Peculiarity of an individual style or topic may occasionally show through
- There are copyright issues in including full texts
- Frequent linguistic features are quite stable in their distributions and hence short text chunks (e.g. 2,000 running words) are usually sufficient
Text initial, middle or end chunks?
- Text initial, middle, and end samples must be taken in a balanced way
Proportion of Samples: Corpus Creation
In stratified random sampling, how many samples should be taken for each category?
- Numbers of samples across text categories should be proportional to their
frequenciesand/orweightsin the target population in order for the resulting corpus to be considered as representative - Difficult to determine objectively, just well-informed and intuitive guess
- Numbers of samples across text categories should be proportional to their
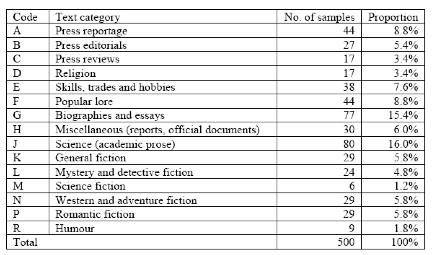
Constant sample size: ~ 2,000 words
Corpus Size
- How large should a corpus be?
- There is no easy answer to this question.
- Krishnamurthy (2001): “Size matters”
- Leech (1991): “Size is not all-important”
- There is no easy answer to this question.
- Size of the corpus needed depends upon the
purposefor which it is intended as well as a number of practical considerations- Kind of query that is anticipated from users
- Are you studying common or rare linguistic features?
- Methodology they use to study the data
- How much work can be done by the machine and how much has to be done by hand?
- For corpus creators, also the source of data
- Are the data in electronic form readily available at a reasonable cost?
- Can copyright permissions be granted easily if at all?
- Kind of query that is anticipated from users
Corpus Size
- Corpus size increases with the development of technology
- 1960s-70s
- Brown and LOB: one million words
- 1980s
- Birmingham/Cobuild corpora: 20 million words
- 1990s
- British National Corpus: 100 million words
- Early 21st Century
- Bank of English: 645 millions words
- 1960s-70s
Different Types of Corpora & Their Uses
General/reference vs. specialized corporaSynchronic vs. diachronic corpora- Monolingual vs. multilingual corpora
- Comparable vs. parallel corpora
- Native vs. learner corpora
- Developmental vs. learner/interlanguage corpora
- Raw vs. annotated corpora
Static/sample vs. dynamic/monitor corpora
