Text Pre-Processing
LIS 4/5693: Information Retrieval and Text Mining
Text Pre-Processing
- Basic pipeline
document → paragraphs → sentences → wordswords and sentences → POS taggingsentences → syntactical and grammatical analysis
Common Text Pre-processing Tasks
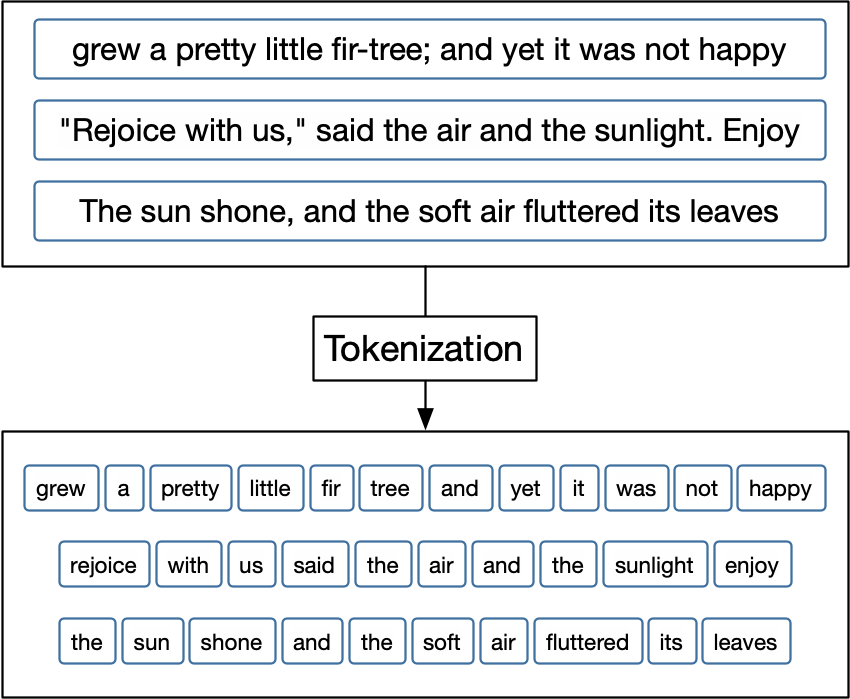
Tokenization
Common Text Pre-processing Tasks
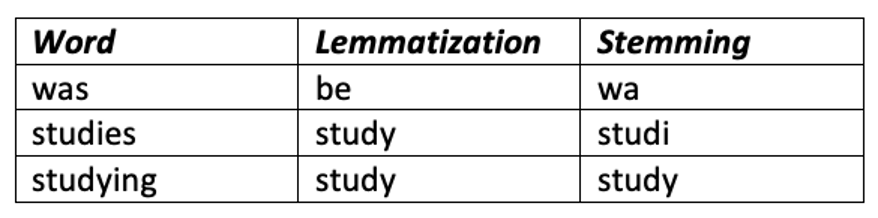
LemmatizationandStemming

Common Text Pre-processing Tasks
Stopwords![]()
![]()

Common Text Pre-processing Tasks
Named Entity Recognization (NER)![]()

Common Text Pre-processing Tasks
Part-of-Speech (POS) Tagging
POS tagging marks words in the corpus to a corresponding word based on its context and definition

Common Text Pre-processing Tasks
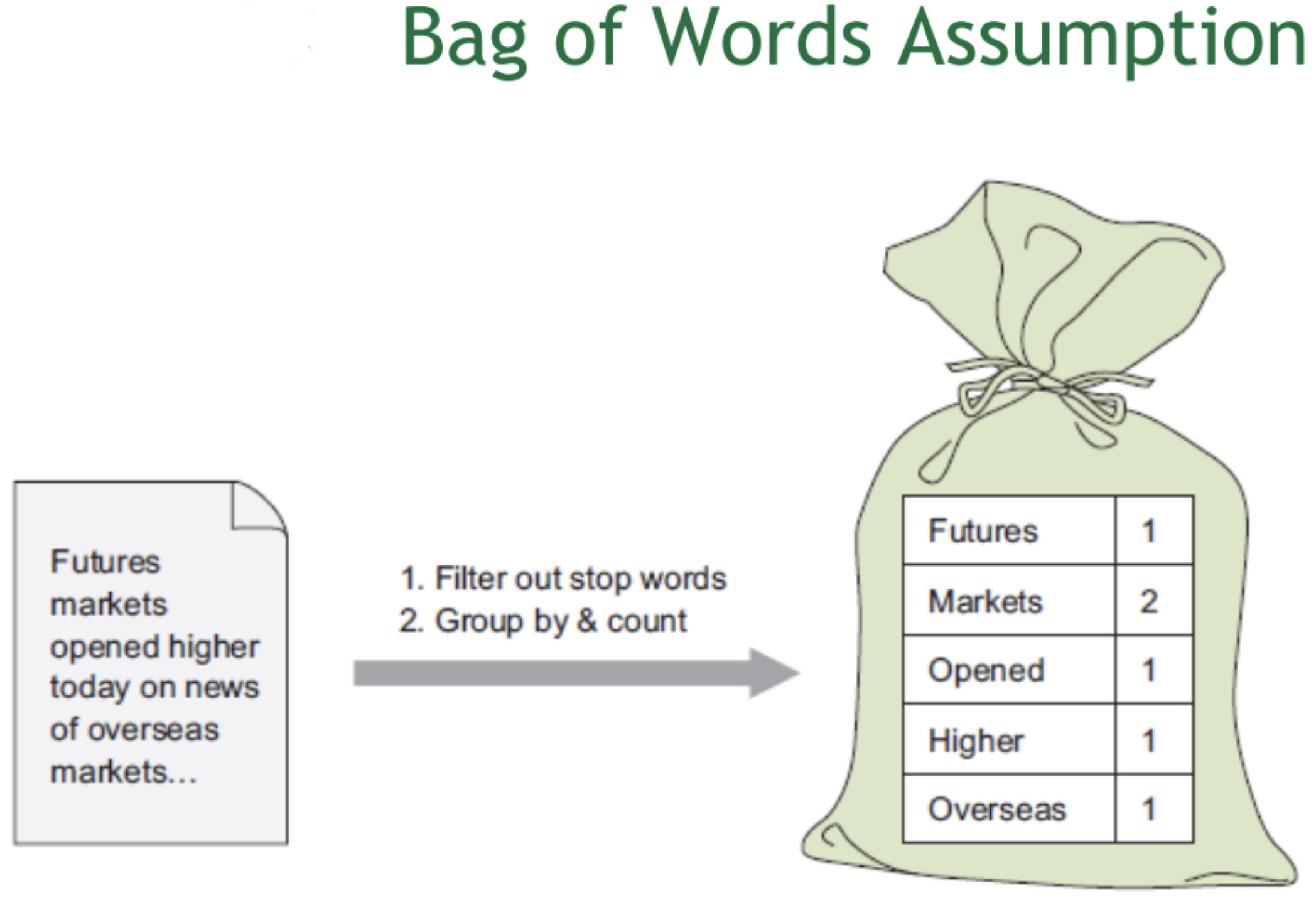
Bag of Words
Common Text Pre-processing Tasks
Term-Document Matrix
- It represents terms as a table or matrix of numbers for a given corpus
- In TDM, terms are represented as rows and documents as columns for a corpus where the number of occurrences of terms in the document is entered in the boxes

Common Text Pre-processing Tasks
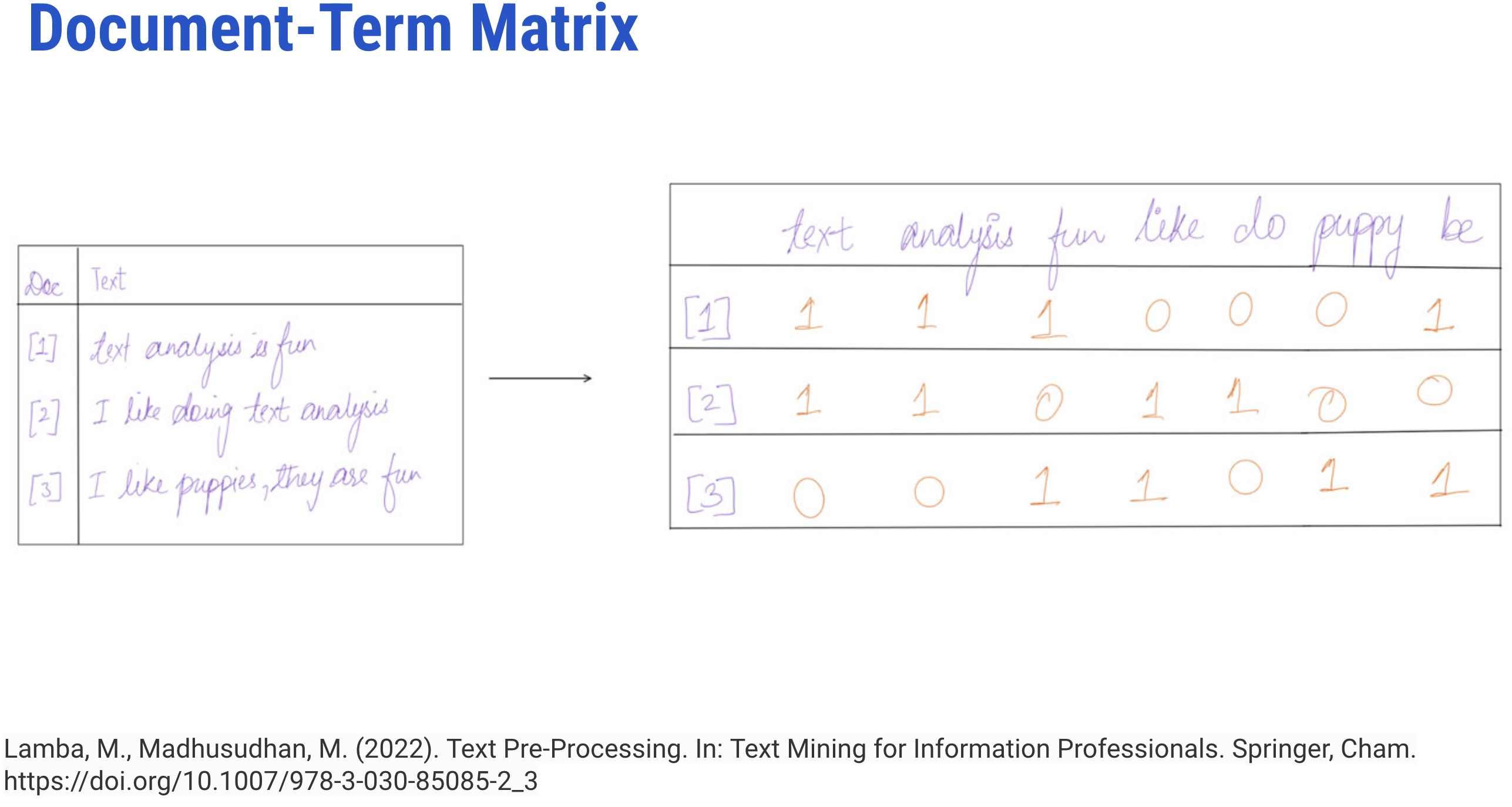
Document-Term Matrix
- It represents terms as a table or matrix of numbers for a given corpus
- It is a transposition of TDM
- In DTM, each document is a row, and each word is the column
Common Text Pre-processing Tasks
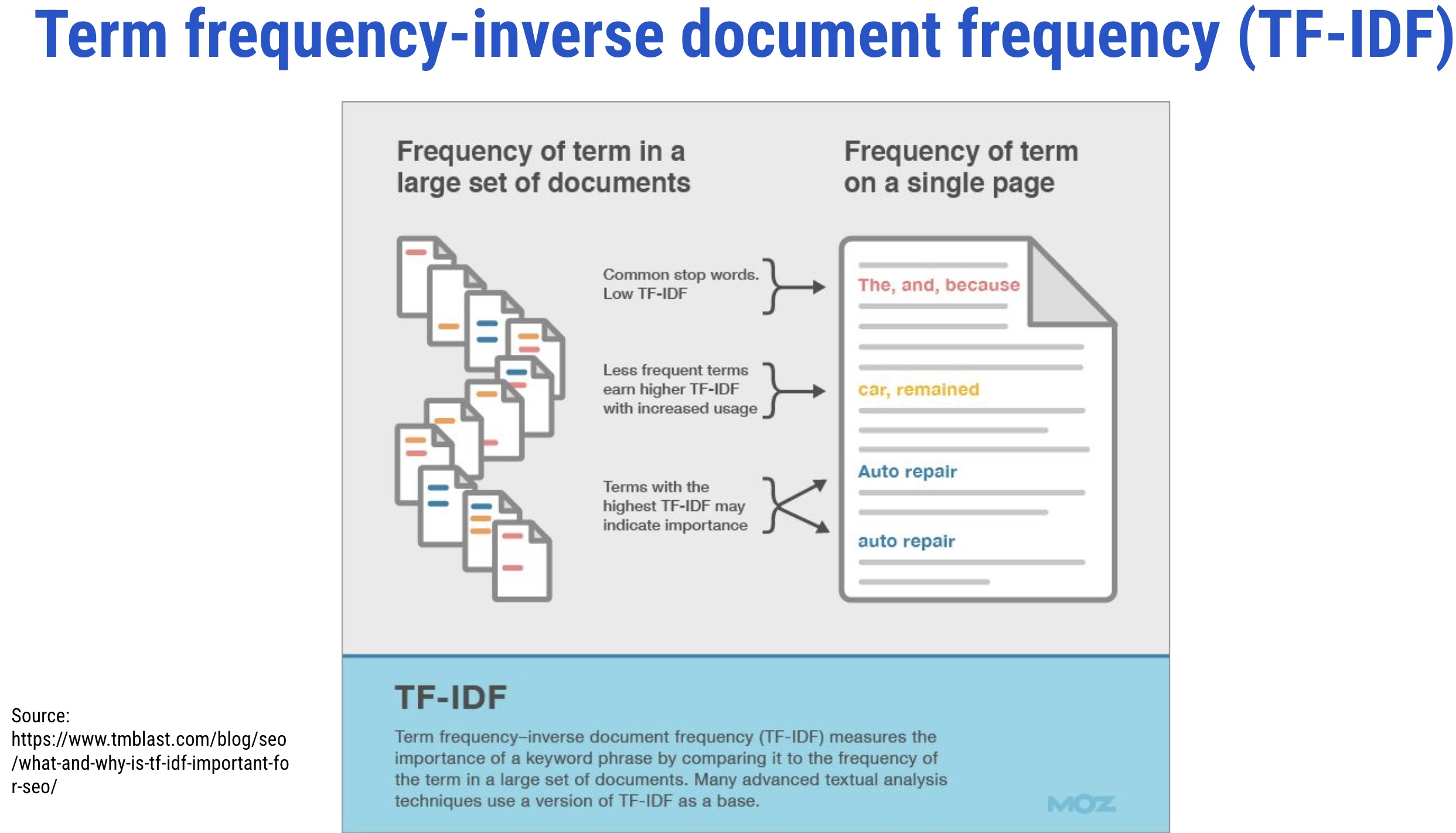
Term Frequency-Inverse Document Frequency (TF-IDF)
- It evaluates the relevancy of a term for a document in a corpus and is the most popular weighting scheme in information retrieval (IR)
- The term weighting is popularly used in IR and supervised machine learning tasks like text classification
- It makes a list of more discriminative terms than others and assigns a weight to each highly occurring term
Common Text Pre-processing Tasks
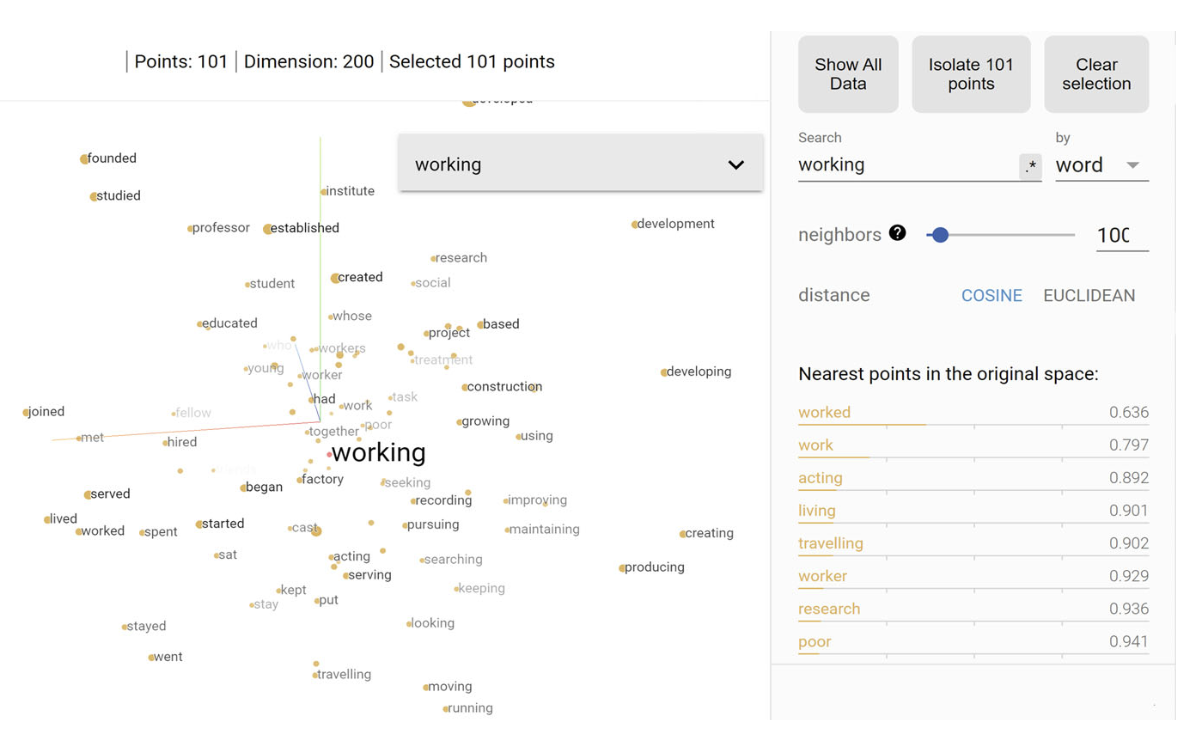
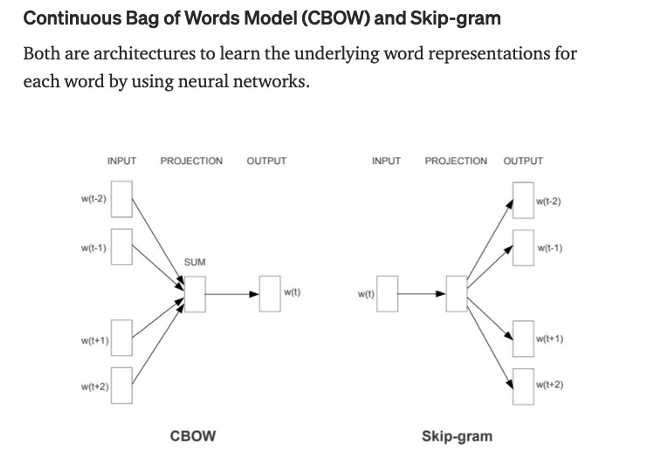
Word Embeddings